
Earlier this year, Snowflake released Column Lineage functionality into general availability to much applause from data governance champions. Now hang on – I know data governance doesn’t have the most gravity as a reading topic, but I promise this will be worth it. In fact, I’ll drop a little surprise at the end, as a carrot of sorts.
In a connected world with ever-growing responsibilities of data security and compliance, understanding where your data comes from and where it’s going is of utmost importance. With Column Lineage, teams can track sensitive data columns in a more streamlined fashion.
So, how does it work?
Snowflake can track the column lineage through data manipulation commands, including CREATE TABLE AS … SELECT (CTAS), MERGE, and INSERT. This is accomplished through the Account Usage ACCESS_HISTORY view (available for Enterprise Edition+), which tracks when user queries read column data or run SQL statements that perform data write operations. That was a jam-packed couple of sentences, so let’s break it down:
Firstly, ACCOUNT_USAGE is a schema under the out-of-the-box provided SNOWFLAKE database. This schema is a treasure trove of views containing object metadata and historical usage data.
Note: By default, the SNOWFLAKE database is only accessible by the ACCOUNTADMIN role, and by extension so is the ACCOUNT_USAGE schema. Other roles can be granted SNOWFLAKE database usage as outlined in the Snowflake docs.
The ACCESS_HISTORY view contains access history of Snowflake objects (tables, views, column) for the past 365 days. Previously, it only contained read operations, but it now includes write operations which allows for the column lineage functionality. Most of the relevant data is stored in columns of the ARRAY data type, so accessing the information requires the (LATERAL) FLATTEN function.
Now, let’s walk through an example of determining column lineage in Snowflake. For this exercise, I had the help of my wonderful colleagues at InterWorks in creating a dataset of fictional dogs for our fictional veterinary care company, InterWags. (Disclaimer: This is a dog-biased fictional company. I do apologize to my cat-owning readers).
I chose a vet care company for a couple reasons: familiarity from a previous job and the Personal Identifiable Information (PII) discussion surrounding pet information. While not always considered a direct path in identifying individuals, a pet’s name, particularly if it is a remarkably unique name, could in theory be tied to an individual. Additionally, there are considerations for password security: How many of your loved ones use their pet’s name in their passwords? I’d bet at least one!
Okay, let’s dive into a hands-on example. First, let’s create our database, our schemas, our table and our view.
CREATE OR REPLACE DATABASE INTERWAGS; CREATE OR REPLACE SCHEMA INTERWAGS.INTERDOGZ; CREATE OR REPLACE SCHEMA INTERWAGS.MARKETING; CREATE OR REPLACE TABLE DIM_PETS ( PET_ID number identity NOT NULL, SPECIES VARCHAR NOT NULL, BREED VARCHAR NOT NULL DEFAULT 'MIXED', FIRST_NAME VARCHAR NOT NULL, MIDDLE_NAME VARCHAR, LAST_NAME VARCHAR, PREFERRED_NAME VARCHAR, AGE NUMBER(3,0) NOT NULL, COLOR VARCHAR NOT NULL, PERSONALITY TEXT, IS_GOOD_DOG BOOLEAN NOT NULL );
Here are some fun, fictional pets for our example:

Thankfully, InterWags has a data governance team that, let’s say, encouraged its data engineers to include a PII tag on columns with data deemed to be sensitive or potentially sensitive. Please reference Snowflake’s docs on Object Tagging for guidance on administering tags.
The PII_TAG has been set up with a rating of the PII sensitivity of a particular column. In this case, we are rating pet names as a sensitivity level of 2.
ALTER TABLE INTERWAGS.INTERDOGZ.DIM_PETS MODIFY COLUMN FIRST_NAME SET TAG PII_TAG = '2';
This tag and accompanying rating should also be applied to FIRST_NAME, LAST_NAME and PREFERRED_NAME.
Now, the data governance team recently heard rumblings of the Marketing team taking a subset of the DIM_PETS data into their own realm for an upcoming project. To identify if any PII data will be exposed, the data governance team requested the data engineers (us) to track down which data points are being used. Rather than taking the social route by just asking, the data engineers naturally went the automated route by leveraging the Column Lineage functionality in Snowflake!
By using the INFORMATION_SCHEMA in the INTERWAGS database, we can query which columns have the PII_TAG attached:
SELECT
COLUMN_NAME
FROM TABLE(
INTERWAGS.INFORMATION_SCHEMA.TAG_REFERENCES_ALL_COLUMNS(
'DIM_PETS',
'table'
)
WHERE
TAG_NAME IN ('PII_TAG') --Enter the relevant tag(s) to check against.
;
Which yields:
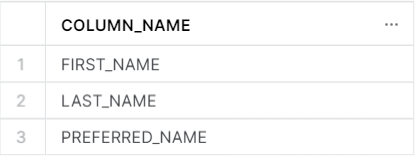
Now, we have the latest and greatest list of columns that are flagged as PII, including: FIRST_NAME, LAST_NAME, and PREFERRED_NAME. With this list, let’s check in the ACCESS_HISTORY view to see where these columns flow. In its documentation on Column Lineage, Snowflake provides an example query on how to obtain object dependency. With a few tweaks, we can use our previous query that identified the columns with PII to more dynamically capture the table’s column lineage as PII tags are added or removed:
SELECT
*
FROM
(
select
directSources.value: "objectId"::varchar as source_object_id,
directSources.value: "objectName"::varchar as source_object_name,
directSources.value: "columnName"::varchar as source_column_name,
'DIRECT' as source_column_type,
om.value: "objectName"::varchar as target_object_name,
columns_modified.value: "columnName"::varchar as target_column_name
from
(
select
*
from
snowflake.account_usage.access_history
) t,
lateral flatten(input => t.OBJECTS_MODIFIED) om,
lateral flatten(input => om.value: "columns", outer => true) columns_modified,
lateral flatten(
input => columns_modified.value: "directSources",
outer => true
) directSources
union
// 2
select
baseSources.value: "objectId" as source_object_id,
baseSources.value: "objectName"::varchar as source_object_name,
baseSources.value: "columnName"::varchar as source_column_name,
'BASE' as source_column_type,
om.value: "objectName"::varchar as target_object_name,
columns_modified.value: "columnName"::varchar as target_column_name
from
(
select
*
from
snowflake.account_usage.access_history
) t,
lateral flatten(input => t.OBJECTS_MODIFIED) om,
lateral flatten(input => om.value: "columns", outer => true) columns_modified,
lateral flatten(
input => columns_modified.value: "baseSources",
outer => true
) baseSources
) col_lin
WHERE
SOURCE_OBJECT_NAME = 'INTERWAGS.INTERDOGZ.DIM_PETS'
AND
SOURCE_COLUMN_NAME IN (
SELECT
-- OBJECT_DATABASE,
-- OBJECT_SCHEMA,
-- OBJECT_NAME,
COLUMN_NAME
FROM
(
SELECT
*
FROM TABLE(
INTERWAGS.INFORMATION_SCHEMA.TAG_REFERENCES_ALL_COLUMNS(
'DIM_PETS',
'table'
)
)
)
WHERE TAG_NAME IN ('PII_TAG') --Enter the relevant tag(s) to check against.
)
;
Note: We have added type casting to some of the flattened fields to VARCHAR in order to remove the quotes around the object names.

We can see from the results that Marketing is using FIRST_NAME, LAST_NAME, and PREFERRED_NAME in an object called INTERWAGS.MARKETING.PETS. We check on this object and see it is a table based on the DIM_PETS Table (specifically where IS_GOOD_DOG = TRUE) made via a CTAS statement. Now, the data governance team can have the appropriate conversation with the Marketing group to ensure the company’s internal and external compliance obligations are met.
While this was a very simplified example, you can imagine the power in a larger data ecosystem the ability to dynamically assess your data governance health using Snowflake allows.
Another important note to make: because popular tools like Matillion and dbt ultimately push Snowflake SQL to the database, lineage can also be tracked when any transformation work takes place in Snowflake. This can be especially useful if different teams are using various tools to manipulate their data in Snowflake, allowing for a centralized path to determining and documenting column lineage.
Alright, alright: Stifle that last yawn. As promised, here is a treat in the form of a picture of my very real dog whose name I will not be disclosing at this time for reasons stated above:
