
In this blog, we are going to talk about natural language; a subset of linguistics that has helped us develop rules and methods that allow patterns in our language to be interpreted, classified and contextualized. The booming field of natural language (NL) research has contributed to some of the most revolutionary technologies in the last two decades including the beloved Siri from Apple, the mysterious powers of Google Search and, more recently, Tableau’s Ask Data feature.
The methods generated from research in NL give us the ability to analyze, interpret and extract insights from our language systematically and programmatically with programming languages like Python. NL has a few key subdomains of study and application that data professionals can leverage to improve how insights are communicated and gleaned from the data. Each of these subdomains also has a plethora of open source and enterprise SaaS solutions that data professionals can get started with rather quickly. In this blog, we are going to discuss most popular of these methods including Natural Language Processing (NLP), Natural Language Understanding (NLU), Natural Language Generation (NLG) and Natural Language Querying (NLQ) and how knowledge in this space can help data professionals.
Before we roll up our sleeves, let us better understand why we need these methods in the first place.
80% of the World’s Data Is Spoken or Written
As data professionals, most of our work is done within a dataset with structure, such as a table in a database, a CSV or a JSON format. An estimated 80% of the world’s data happens to be spoken or written data in the form of documents, messages, phone calls, social media interactions and surveys. That’s right—our structured world only makes up a small portion of the data pie, so why are we talking about this now?
Text Analysis Paralysis
Text data has been seldom used for business analysis or practical analytical problem-solving because of the effort required to wrangle unstructured data into a format that can be evaluated at scale. It can also be difficult to find a practical application for natural language methods. This avoidance often results in organizations hiring employees to manually review every line of text data such as customer reviews, surveys or basic paperwork. When you are talking about thousands of text records, this work is monotonous and can often result in biased interpretation and skewed insights. We don’t want that, do we?
Natural language methods in practice would not aim to replace human interpretation of text and qualitative data; they would simply augment the analyst’s toolbox to help cut through noise and identify trends based on language used in the text. Essentially, these methods could help reduce significant amounts of time spent on manual review and deliver more efficiency to qualitative analytics programs.
Language = Trust
Natural language techniques can also help data professionals improve their process of working with structured data and designing user-centered products. At InterWorks, we always strive to build solutions that make insights accessible to the lowest common denominator of users with a minimal effort on their behalf, often in the form of a report or a dashboard. The language used around the data in question and what decisions they are influencing is at the core of how these tools are built. Language contextualizes how business rules are written, encodes our communication and establishes trust between parties. As our language continues to grow in complexity, a set of tools is required to help users more efficiently communicate, understand and personalize information, whether it be a company messaging their customers or an analyst delivering information to their stakeholder team.
Bringing Data Literacy to the Masses
The dichotomy of data literacy vs. illiteracy is quickly dissolving with the growing suite of BI tools designed to deliver curated analytics to a wide range of audiences and the growing demand of data skills in all roles. Despite the growth in data competency and supporting tools, the analyst still acts as the glue between the data and those who act upon it by spending a sizable portion of their time repetitively interpreting and providing recommendations on the data. In many cases, these repetitive, ad hoc tasks could be informed through self-service but aren’t because of insufficient education and time to build the necessary tools.
The adoption of different NL techniques in an analytics function could help solve these inefficiencies in the analyst’s workday and shift their efforts to more impactful initiatives. Business intelligence giants (like Tableau) have begun to take note of how NL can add this value to customers and have begun to invest in tools that will help them do so in a BI workflow with assisted report-writing and analysis of text data.
Now for the fun stuff. We’re going to break down the related, but unique, subdomains of natural language that are being used today and that will grow in popularity in coming years. So far, we have only looked at NL techniques in a modern context, but they have been in practice for well over 50 years with the same goal we have today: to create better systems of understanding, classifying and analyzing our complex language systems. The most practical application for NL techniques is in business because of the tight, unique parameters that characterize the language and data of an organization, such as a company’s products, customer types and customer behavior.
Natural Language Processing
Before diving into other methods, we should first introduce the most popular of these subdomains that you have likely heard used in data science and advanced analytics circles. Natural Language Processing is an umbrella term for the collection of techniques that categorize various attributes and patterns of language into simplified, classified collections of records that can then be used for analysis, understanding and interpretation. The most common are text pre-processing techniques such as the following.
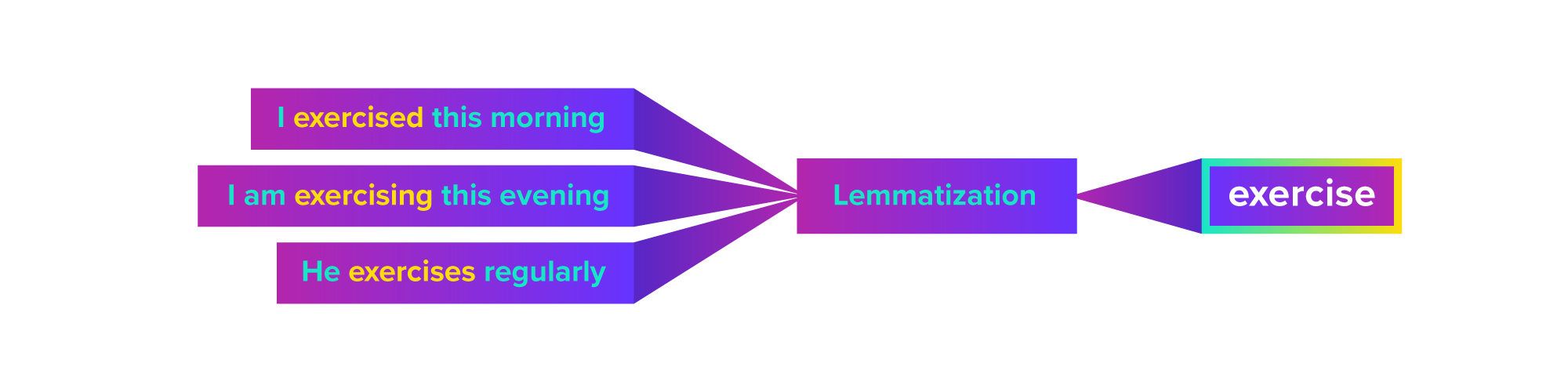
Lemmatization – The process of stripping a word to its barest lexical root. For example, the words exercising, exercised and exercises all have the root word exercise. When lemmatization is applied, each of these variations in a body of text would be processed as the root word exercise:
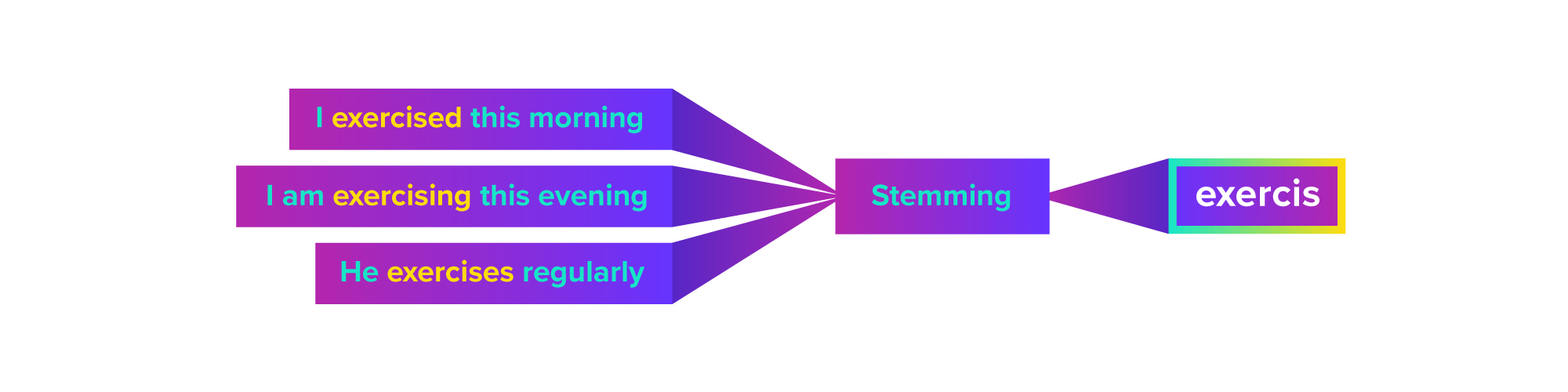
Stemming – Conceptually like lemmatization, stemming is a process that strips a word to its stem, or the word without any affixes and prefixes. For example, the words exercising, exercised, and exercises would have the stem of exercis- :
Stop Word Removal – The process of removing filler words such as a, the, is, was, etc. from a body of text. This is a common first step in text processing as it is an easy way to remove information that serves no real value:

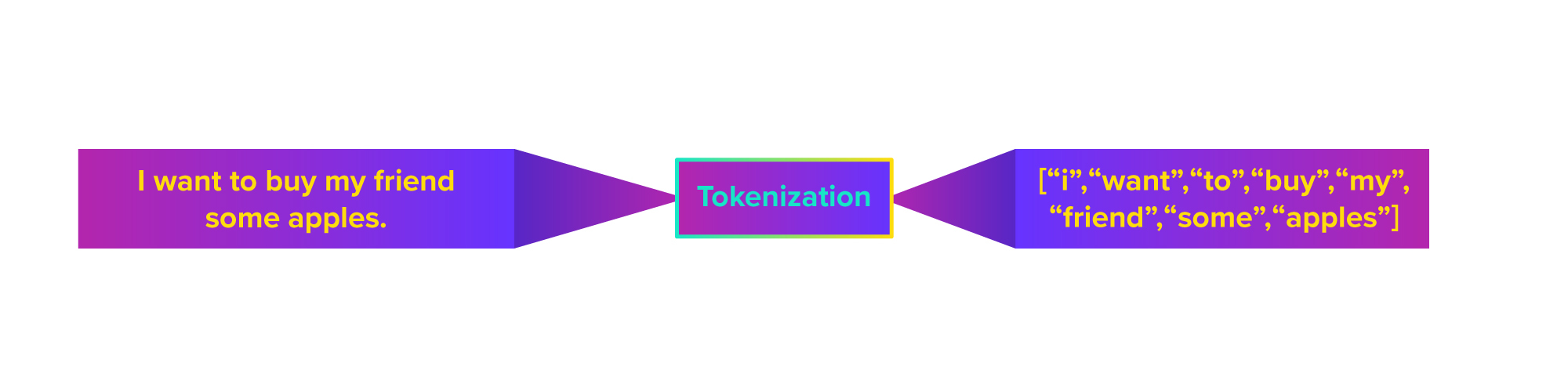
Tokenization – The process of breaking a chunk of text into smaller, more meaningful pieces of text. Typically, tokenization is performed by splitting a sentence or record of text into individual words so they can be analyzed in a singular context and as a part of a larger body of text:
These methods are considered ‘pre’-processing because they are steps taken to simplify text data by putting it into its most raw form, with the goal of making the data easier to interpret by different NL processes.
Also encompassed within the NLP ecosystem are the subsets of Natural Language Understanding, Natural Language Generation and Natural Language Querying. Often, these subtopics are treated as being separate from NLP; however, NLP is what builds the foundation and infrastructure for these topics and the underlying methods.
Natural Language Generation (NLG)
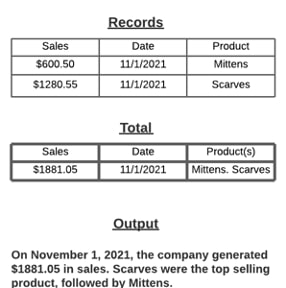
NLG is a collection of processes that convert structured or aggregated data into a natural language output interpretable by humans. This is mostly found in the form of chat bots, virtual assistants or predictive text engines (what magically “reads” your mind when you vaguely type words into a browser search). NLG arguably shows the most promise for data professionals, for it has spawned a whole new sector of technologies that aim to help analysts automate, curate and scale their reporting processes. Technologies like Arria NLG, Wordsmith and Narrative Science make this simple by offering plugins to popular BI tools, as well as a dedicated platform that can be used in custom apps to assist with report-writing and distribution of insights through email or Slack.
NLG outputs are descriptive in nature and often require data to be pre-aggregated, meaning that it only deals with putting data into a natural language summary or paragraph, which is easily readable by humans and is grammatically correct.
Natural Language Querying
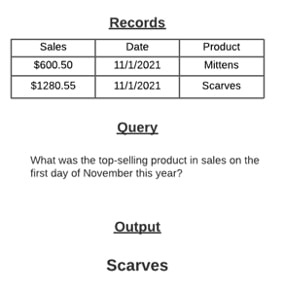
NLQ is the layer of NLP which gives users the ability to intuitively query through data using natural language rather than relying on knowledge of languages like SQL. Simply put, NLQ provides the infrastructure to allow users to talk to their data, similar to Tableau’s Ask Data feature. In most cases, activating NLQ on your data can be a large undertaking as it assumes the data in question is of a certain quality and requires contextualizing each dataset element by factoring in its data type, how it is used in the context of our natural language, and what it needs to pair with to yield a meaningful, interpretable output.
Like NLG, Natural Language Querying is also seeing widespread adoption as BI platforms race to make it seamless for non-technical users to derive answers from their data. Platforms like Tableau, ThoughtSpot and Qlik all have some version of a feature that allows a user to ask an ad hoc question and return an interpretable, visualized result.
Natural Language Understanding
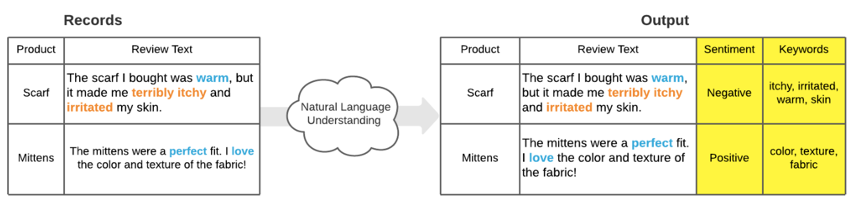
Similar to NLG, Natural Language Understanding involves the methods of classifying, breaking down and organizing patterns and parts of speech to better understand intent. NLU deals with structure, syntax and semantic elements of speech in way that it can be interpreted into an output that picks up on the additional context of language undetected by other subsets of NL.
The most popular NLU method is modeling sentiment in text or voice-based records, which involves the classification or scoring of records based on analyzing patterns of speech, the syntax of words in the record, and the meaning of those words in everyday language to determine how positive or negative they are. Sentiment analysis is one example that is relatively easy to implement and is seen across industries to batch-score troves of customer interactions, online reviews or qualitative survey feedback. Tools such as MonkeyLearn, Amazon Comprehend and Salesforce Einstein support sentiment analysis and other NLU processes as out-of-the-box features. Platforms like Alteryx and Dataiku also support NLU tasks and customization with third-party plugins.
The Future of Natural Language
Without a doubt, we are headed towards a future where natural language methods will become essential for data practitioners—in fact, we are already there. For developers and analysts, you can begin to understand text data better with Natural Language Processing and deliver more personalized customer experiences with the digital products you design using Natural Language Generation and Querying.
The opportunities for data professionals to integrate these NL techniques and technologies into their analytics function and processes continues to grow. Today, there is a large selection of platforms and integrations that can get you up and running with these techniques quickly, whether it be analyzing the sentiment of a standalone column of text in your data, aiding your analyst team in generating written narratives in Tableau Server or setting up your tables in Snowflake for natural language querying. If you’re curious about how your team could benefit from these NL technologies, reach out to our team of experts. We’d love to help!