
We have all seen this problem in data transformation: names automatically becoming CAPITALISED NAMES or all lowercase names. If we have a list of cities consisting of only one word, it is quite straightforward to capitalise the first one using the following code:
UPPER(left([Data],1)) + LOWER(right([data],LEN([data])-1))
However, what if our name field consists of 1-4 last names, one first name and 0-1 middle names? Using basic SQL and RegEx knowledge, the following code will help you work around the Tableau Prep limitation of lacking the command TitleCase().
The example is built upon a pretty common scenario of LAST NAME, FIRST NAME MIDDLE NAME but can be easily adjusted. If you have a different scenario in mind you’d like some troubleshooting help with, contact me directly and I will do my best to help you figure it out.
If you are not familiar with RegEx (regular expressions), I’ll have another blog coming out soon about the split method – this will be an alternative to RegEx, so check back for that link once it’s available.
A Look at the Outcome in Prep
Below, you can see the original input (right column) and the transformed field (left column):
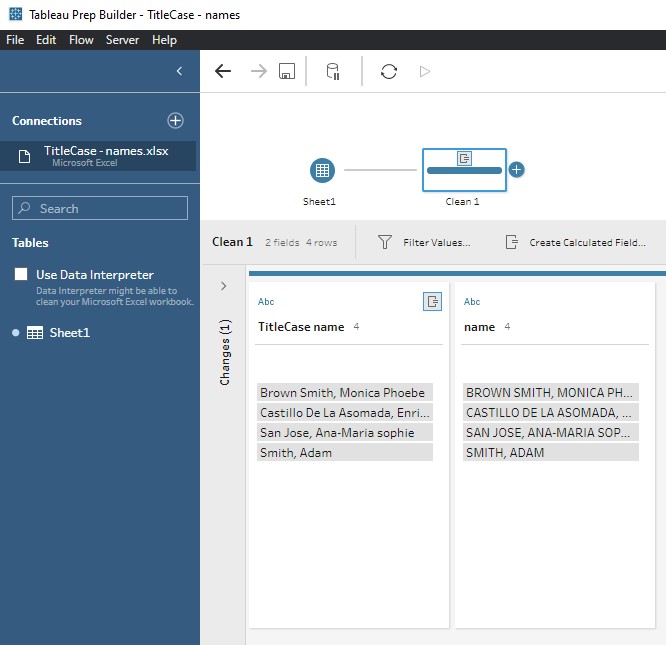
The Solution
You can copy and paste the below code into your Prep flow, or feel free to download the attached Tableau Prep flow found at the bottom of the blog post.
Tip: Working with a different field than [name] ? Copy and paste the code to MS Word and use the Replace tool to change all 23 references.
//Title Case in Tableau Prep //by Igor Garlowski from InterWorks // This is the base query that we edit multiple times to get all the first, middle and last names. Edit regex in https://regex101.com/ to match your records, then copy paste it changing the NUMBER to receive all names with the first letter being capitalised. //Original code comment structure //Last name (4), First name (1), Middle name (1) //Original code comment: Last name (1), second last name (2), third last name (3), forth last name (4), first name (5), middle name (6) //Original code based on //REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',NUMBER) //Parts where you want to paste your code //REGEXP_EXTRACT_NTH([TABLE_NAME], 'REGEX CODE',NUMBER) //Below we combine the above with the following code which makes the first character upper and the rest lower //UPPER(left([Data],1)) + LOWER(right([data],LEN([data])-1)) //Lastname UPPER(left(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',1) ,1)) + LOWER(right(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',1) ,LEN(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',1) )-1)) + //Second last name if it exists IF REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',2)!="" THEN UPPER(left(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',2),2)) + LOWER(right(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',2),LEN(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',2))-2)) ELSE "" END + //Third last name if it exists IF REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',3)!="" THEN UPPER(left(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',3),2)) + LOWER(right(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',3),LEN(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',3))-2)) ELSE "" END + //Fourth last name if it exists IF REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',4)!="" THEN UPPER(left(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',4),2)) + LOWER(right(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',4),LEN(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',4))-2)) ELSE "" END //, + ", " + //First name UPPER(left(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',5) ,1)) + LOWER(right(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',5) ,LEN(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',5) )-1)) + //Middle name if it exists IF REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',6)!="" THEN UPPER(left(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',6),2)) + LOWER(right(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',6),LEN(REGEXP_EXTRACT_NTH([name], '^(\w*)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?)(\-?\.?\s?\w*\.?),\s?(\w*)\s??(.*)',6))-2)) ELSE "" END
More RegEx Resources to Come
Still overwhelmed by the RegEx? Have no fear! The split solution is coming, so be sure to come back for it. I also plan to tackle this solution in Alteryx in another forthcoming post, so be on the lookout for it.
If you have any questions about this or any other solution, feel free to reach out to me directly via email or LinkedIn.