
Corporate AI Projects are High Risk, High Return
McKinsey report that the adoption of AI within businesses has surged in the last year, with 72% of companies now using AI in at least one business function (ref).
There’s a problem though: Most internal AI initiatives fail to deliver value. Research by the RAND corporation suggests that up to 80% of AI projects fail, twice the rate of technology projects that don’t involve AI. (ref). TechRepublic puts the failure rate at 85% ref).
On the other hand, where AI projects succeed, they win big. A report commissioned by Microsoft but undertaken by IDC showed that investments in AI showed an average return of 250% (so $3.5 back for every $1 invested) (ref).
For that to fit with the 80% failure rate reported above, we should expect those projects that do succeed to return $12.50 for every $1 invested.
The way to win in an environment with high risks and high returns is to spread your bets. Instead of investing in a few large projects, be prepared to try many small-scale initiatives, see what works and iterate on the successes.
So, how to find those small-scale initiatives that are most likely to succeed? One approach is to find projects that fit the M.A.Y.A design principle.
M.A.Y.A. — Most Advanced Yet Acceptable
M.A.Y.A is a design principle conceived by Raymond Loewy. Loewy, sometimes referred to as “The Father of Industrial Design,” was responsible for many iconic 20th century designs from the 1957 curvy Coke bottle to the interior of Concorde.
His idea is that a new product is most likely to succeed if it feels both innovative and familiar. It has to be new enough to be interesting, but familiar enough so that it won’t scare or confuse.
A great product idea is one that people understand the moment they see it, and can immediately start getting excited about. By contrast, a product idea might make sense on paper, but if the value isn’t clear to the people who would use it, then it’s probably not a great idea in the first place.
Applying this principle to AI projects, the ones most likely to succeed will be ones where:
- The value is immediately clear.
- They enhance rather than disrupt existing business processes.
- They can integrate with the existing technical infrastructure.
An Example Use Case for AI that Follows the MAYA Principle
If you’ve purchased anything from Amazon recently, you may have noticed a new feature. Many Amazon products have hundreds or thousands of reviews. Nobody is going to read through all those reviews before buying a kettle, but now they don’t have to. Amazon offer them an AI generated summary as “Customers say:”
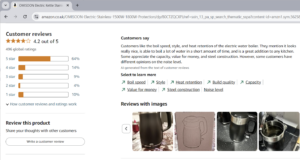
This feels like a great use case for generative AI that fits well with the MAYA principle:
- It offers something new.
- The value is immediately clear.
- It enhances rather than disrupts existing services.
Looking the mix of different star ratings, not everyone likes this particular kettle, yet the criticism in the summarised review seems quite muted. We don’t know what kind of system prompts were given to Amazon’s large language model and so to what extent it might be putting an unrealistically positive spin on the reviews.
Can We Recreate This Functionality?
At InterWorks, we wanted to see if we could reproduce these kind of summaries using data in Snowflake. By controlling the system prompt, we can create more detailed summaries that don’t gloss over negative points raised by reviewers.
We used a publicly available dataset of Amazon Reviews from 2023, uploaded to our internal sandbox Snowflake instance.
Narrowing down to a single product, here’s what the raw review data looks like for a particular model of chest freezer. This model had 335 reviews in 2023:
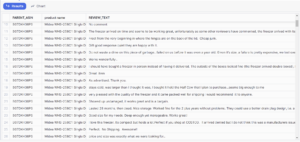
For this example, we’re using the “mistral-large” large language model to generate the summary.
We fed the reviews to the large language model with the following system prompt:
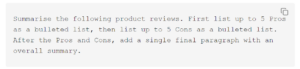
Here’s the output, saved as text in a newly created product summary table:

Automatically generated summaries like this can be used for more than product reviews.
Most reports and dashboards today work by adding up columns of numbers and grouping them by predefined categories. Free text can be displayed at a detailed level, but is otherwise ignored. A few years ago, organisations were able to gain significant new insights just by looking at the numbers sliced and diced in different ways. Today, it feels like much of the juice has been squeezed out of that particular lemon.
Now we can aggregate columns of free text as well as just columns of numbers, this opens up some interesting new possibilities:
CRM Summaries
How is our relationship with a particular customer right now? Are there any particular sensitivities to be aware of? Do they love us, or have we disappointed them somehow and are trying to win back their goodwill? A quick summary of the current state of a customer relationship can really help anyone just starting to work on a customer account.
Incident or Fault Reports
Freeform text entered into an incident report by people on the ground may point to issues that aren’t covered by the standard flags and categorisations. Using AI to analyse free text within incident reports could highlight emerging issues that aren’t being picked up by existing analyses.
Surveys
Most surveys today consist of lists of questions with mainly multiple choice answers. Surveys are designed this way mainly because the data gathered is easier to analyse, not because it’s the best way to illicit information. Surveys with tightly constrained questions, each with a limited set of possible answers may miss important issues because the right question hasn’t been asked or the true answer isn’t one of the proscribed options. What if, instead, we had surveys that just said, “Tell us what you’d like us to know?”
TL;DR
- The path to successful AI projects involves spreading your risk and making many small bets on promising looking initiatives.
- Those initiatives most likely to succeed are those that can offer something new but are able to build on something familiar.
Our example shown above using an LLM to analyse Amazon reviews was created in just a few hours in Snowflake. Our data engineers could implement similar functionality on your corporate data, with some additional controls to make it robust enough for production use, in just a single data sprint.
To find out more, contact us here.