
If you are familiar with SQL, you would be familiar with the concept of aggregate functions. For those who are still a bit fuzzy on what these aggregate functions intend to do, here’s a quick couple of quick examples:
- When you want to find the total sales of all the product categories in your sales dataset, you would simply do a SUM function.
- In case you want to determine the minimum and maximum salaries of employees in your organization, you would simply do a MIN/MAX function.
These are two examples of aggregate functions, which are functions that calculate a value based on a group of records in a set of data.
Similar to these example aggregate functions above, Snowflake has two additional incredibly useful aggregate functions: MIN_BY and MAX_BY.
Read on to know more!
How Do MIN_BY and MAX_BY Act on my Data?
Imagine you have a dataset showing the number of sales per product across different stores in your organization, and you wanted to know the total number of sales for each store. Now, usually if you write a SQL query with the SUM function, your query will look something like this:
select
"STORE_ID"
, sum("SALES") as "TOTAL_SALES"
from "SALES"
group by "STORE_ID"
order by "TOTAL_SALES" desc
;
This could return an output similar to the following example:
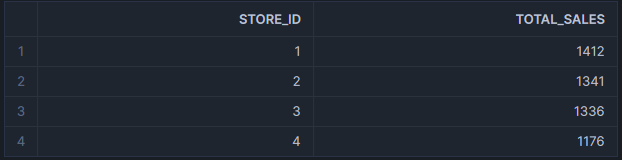
This is great for identifying the stores and viewing the total sales per store, but there may be other information that you wish to find that is not so simple and would involve a more complex query.
Best-Selling Product per Store — MAX_BY
For example, what if we wanted to quickly identify the best-selling product for each store? Previously, this would be harder to achieve in a single query without relying on more complex functionality, such as QUALIFY statements, and could increase the complexity enough to prevent other parallel results in the same query. However, with the new MAX_BY function in Snowflake, you can reduce this query to a single line, which will look something like this:
select
"STORE_ID"
, sum("SALES") as "TOTAL_SALES"
, max_by("PRODUCT", "SALES") as "BEST_SELLING_PRODUCT"
from "SALES"
group by "STORE_ID"
order by "TOTAL_SALES" desc
;
This could return an output similar to the following example:
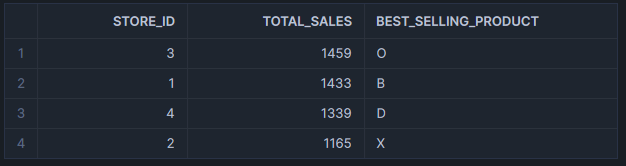
This is a great demonstration of what the MAX_BY function can achieve, as we can easily see which product had the most sales without needing to overcomplicate our query.
Worst-Selling Store per Product — MIN_BY
We could also very easily flip this on its head and consider which stores are the worst at selling specific products. This is a great opportunity to leverage the MIN_BY function:
select
"PRODUCT_ID"
, min_by("STORE_ID", "SALES") as "WORST_SELLING_STORE"
, min("SALES") as "SALES_IN_WORST_SELLING_STORE"
from "SALES"
group by "PRODUCT_ID"
order by "PRODUCT_ID"
;
This could return an output similar to the following example:
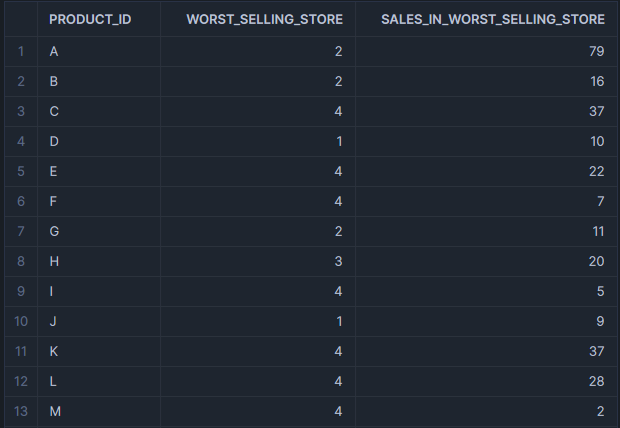
As you can see, we can identify the worst selling store and retrieve other aggregate information in the same query. Not only does this make querying easier, this also improves the performance.
Returning Multiple Values
So far, we’ve demonstrated using MAX_BY and MIN_BY to return single values. These functions are actually capable of returning multiple values in a single array if an optional input is leveraged. For example, we can identify the five best-selling products and the three worst-selling products for each store:
select
"STORE_ID"
, max_by("PRODUCT_ID", "SALES", 5) as "BEST_SELLING_PRODUCTS"
, max_by("PRODUCT_ID", "SALES", 3) as "WORST_SELLING_PRODUCTS"
from "SALES"
group by "STORE_ID"
order by "STORE_ID"
;
This could return an output similar to the following example:
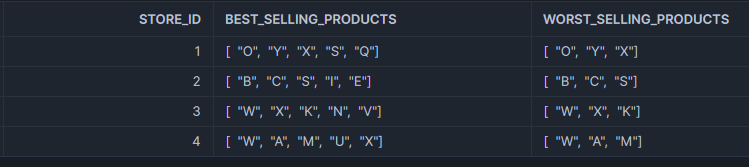
As we can see, this query returns a couple of arrays that show the best-selling and worst-selling products for each store.
A More Complex Example
To wrap up, let’s demonstrate a more complex example that demonstrates the versatility of this functionality. For this example, consider a large dataset of sales per store, product and date, spanning several months. This data would look something like this:
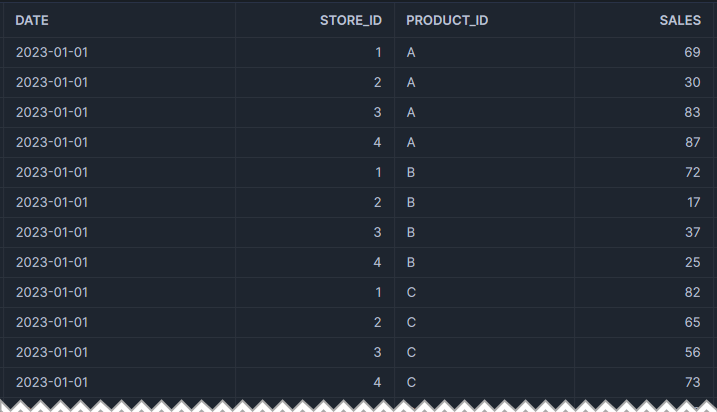
With this data, we can do a handful of cool tricks to demonstrate the power of the MIN_BY and MAX_BY functions:
select
"PRODUCT_ID"
, max_by("SALES", "DATE") as "VALUE_OF_MOST_RECENT_SALE"
, max_by("DATE", "SALES") as "DATE_OF_HIGHEST_SALE"
, max("SALES") as "VALUE_OF_HIGHEST_SALE"
, max_by("STORE_ID", "SALES") as "STORE_OF_HIGHEST_SALE"
, max_by(
object_construct(
'date', "DATE"
, 'store_id', "STORE_ID"
, 'value', "SALES"
)
, "SALES", 5
) as "BEST_SELLING_EVENTS"
from "SALES"
group by "PRODUCT_ID"
order by "PRODUCT_ID"
;
This could return an output similar to the following example:
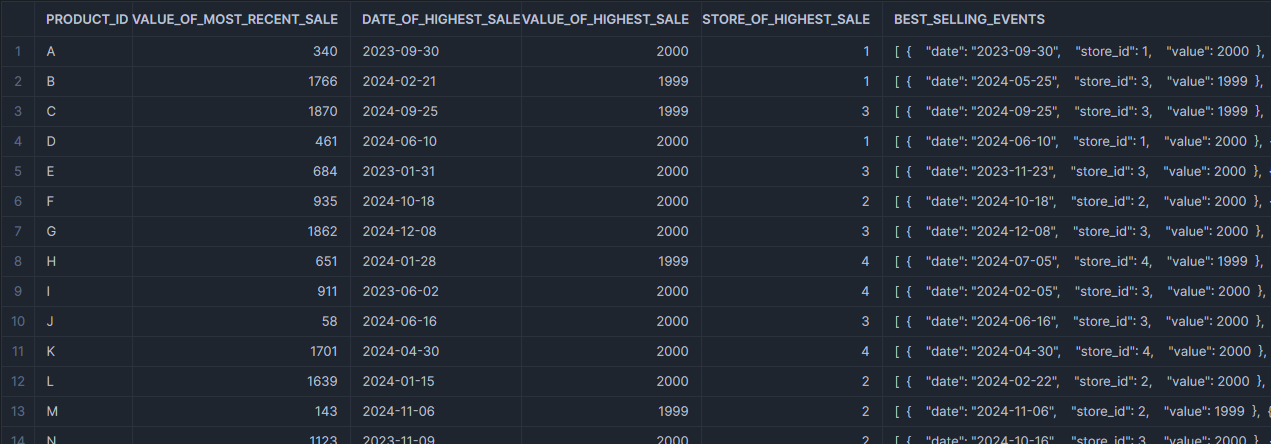
The most interesting output here is the “BEST_SELLING_EVENTS” field, which shows the five best sales events for the product. The values in this field are arrays of individual objects. Here is an example of one of these values:
[
{
"date": "2023-03-20",
"store_id": 2,
"value": 1998
},
{
"date": "2023-02-19",
"store_id": 2,
"value": 1997
},
{
"date": "2023-09-02",
"store_id": 2,
"value": 1997
},
{
"date": "2023-04-15",
"store_id": 2,
"value": 1997
},
{
"date": "2023-09-28",
"store_id": 1,
"value": 1996
}
]
These are just a few examples of how you can leverage MIN_BY and MAX_BY to simplify queries in Snowflake.