Being an avid music lover, I always wondered about various factors that make up an entire song. This project provided me an opportunity to do so. I stumbled upon an amazing data source in Kaggle that had authentic Spotify data with a lot of key features for each song scraped using Spotify’s API. Once I obtained the dataset, I sanitized the data (eliminated tracks that brought in characters beyond the ASCII range), created some calculated fields to better understand insights and starting building my dashboards.
My Tableau story consists of three dashboards:
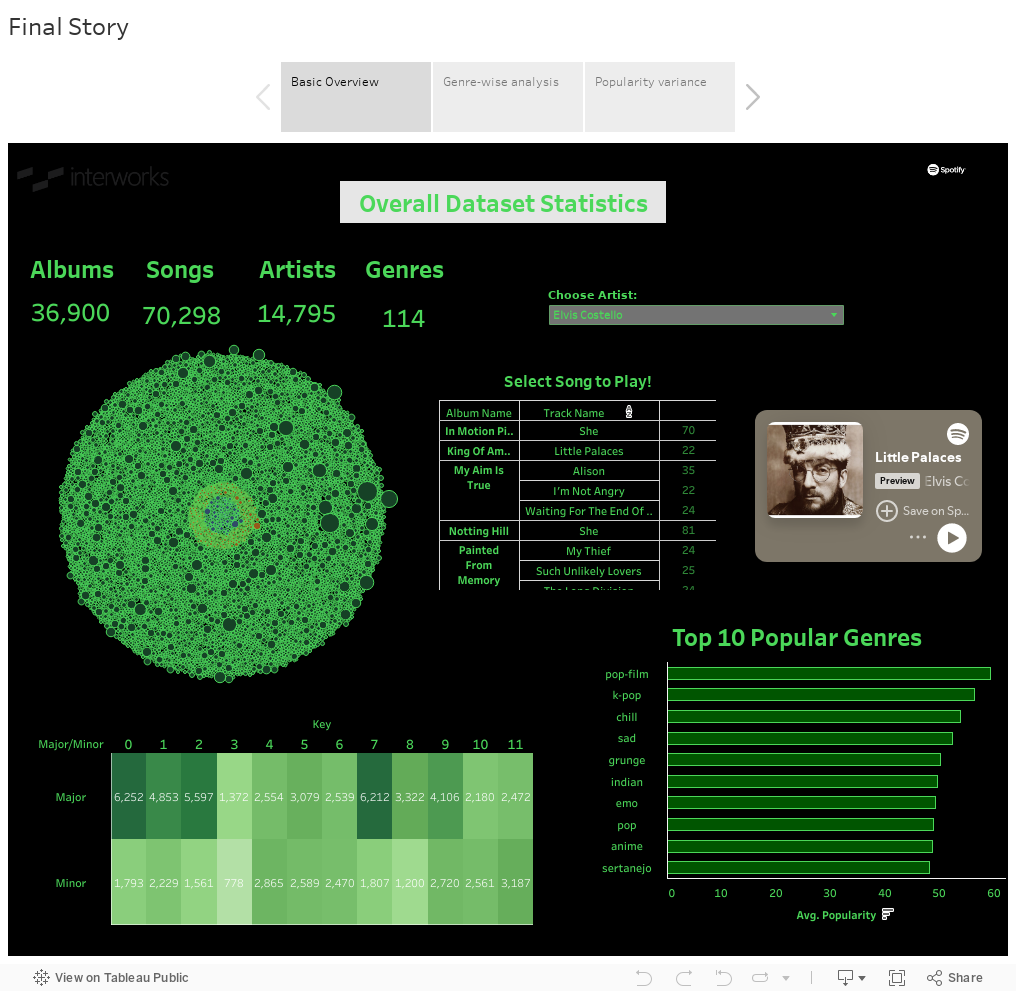
The first dashboard shows some basic stats that provide an overall flavor of the dataset used for this purpose. Feel free to choose your artist of choice and click on the song to play some music while looking through!
(Key assumption: If a song has mutliple artists, only the primary artist has been given ownership . For example, “Perfect” has both Ed Sheeran and Beyonce, but in this analysis, the song will only appear under Ed Sheeran’s list of tracks.)
The second dashboard digs a bit deeper into each genre to see the spread of different attributes such as temp, valence etc. of the Top 50 songs within each genre. Note that in some genres, you will be able to see a lot more than 50 data points. This is because Spotify usually rates songs with a popularity score between 0-100 and if more than one song have the same score, they have been ranked the same in this analysis to give an accurate analysis.
The last dashboard aims to see if popularity changes because of two key factors of any song: whether it has explicit content or not and the mode in which the track has been composed.