
This series focuses on our partnership with ThoughtSpot, its valuable data solutions and the value we provide to clients as a team.
Welcome to part three of our introductory series on ThoughtSpot. If you missed the first two blogs, the first one lays the foundation for our partnership with ThoughtSpot and the second walks through the hierarchy of processes within the solution. Today, we are going to start the first of two blog entries on data. Data is why we’re here, insights into our data is what we are seeking in ThoughtSpot, and probably by now, you have discovered that connecting to and setting up your data properly is a crucial step in making ThoughtSpot perform at its best.
Find the Right Place for Your Data
If you’ve been in the BI and analytics space for a while, you’ve probably been exposed to many different ways to connect to data. ThoughtSpot has its own methods, just like any other platform. As a reminder, there are two ways to implement ThoughtSpot at your organization: on-prem and cloud. For the purposes of this blog, we will focus largely on the SaaS, or cloud, offering, but I do want to make sure we cover the basics of the on-prem solution, too.
With on-prem, ThoughtSpot has its own internal database called Falcon. This is much like a Hyper extract in Tableau or other proprietary data store for a BI toolset. With Falcon, users can import data from any local database connection, flat files or any other data feed. ThoughtSpot runs on Linux, so there is a CLI for performing these tasks, as well as importing data in the GUI or through a workflow. In any scenario, the data is being consumed into ThoughtSpot’s native data store—the Falcon database:
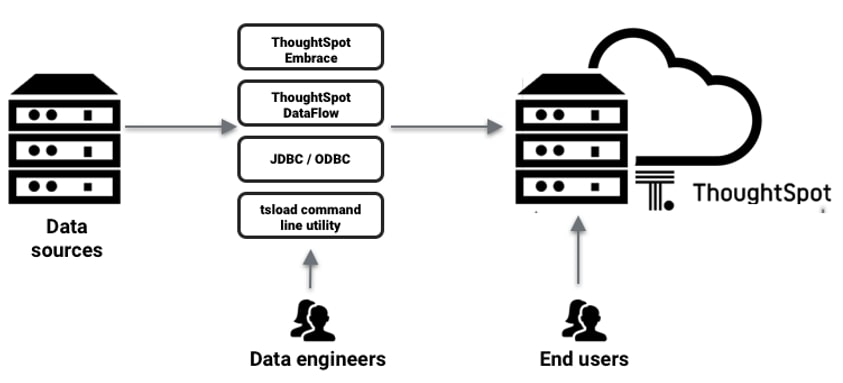
ThoughtSpot indexes the columns appropriately for a very fast search experience. If you have the on-prem version of ThoughtSpot, you also know that there is an option to connect to data LIVE through Embrace. Embrace allows for customers who use Snowflake or Redshift to still perform live query searches on their data without importing the data into Falcon first.
Connecting Data in ThoughtSpot Cloud
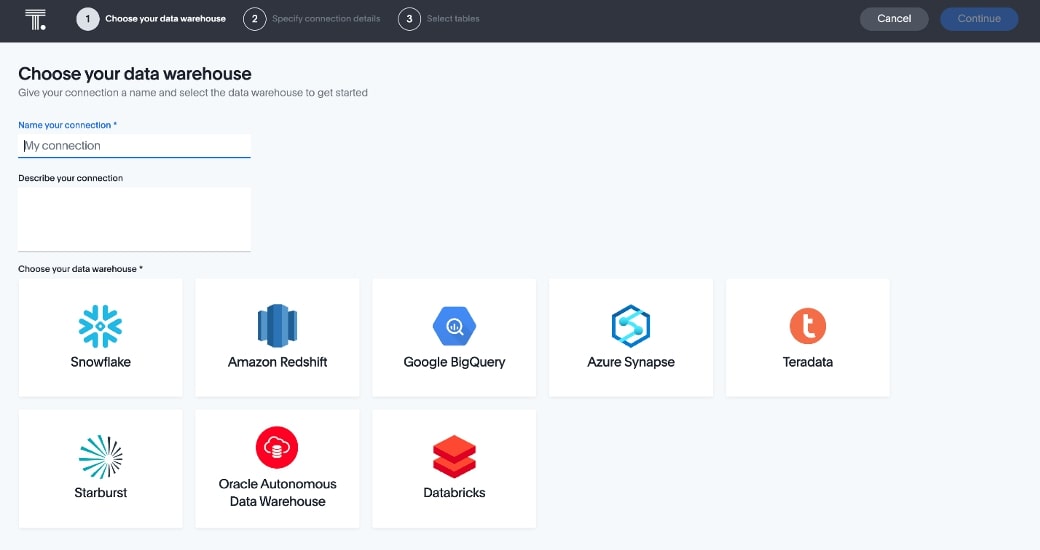
For the cloud or SaaS customers, data management is as easy as any BI tool I’ve worked with. While connections are limited to specific cloud data platforms currently, ThoughtSpot does have a roadmap to continue to build out native connectors to cloud data platforms. When it comes to connecting your data in ThoughtSpot Cloud, it really is as easy as 1-2-3.
Step 1: Add a connection
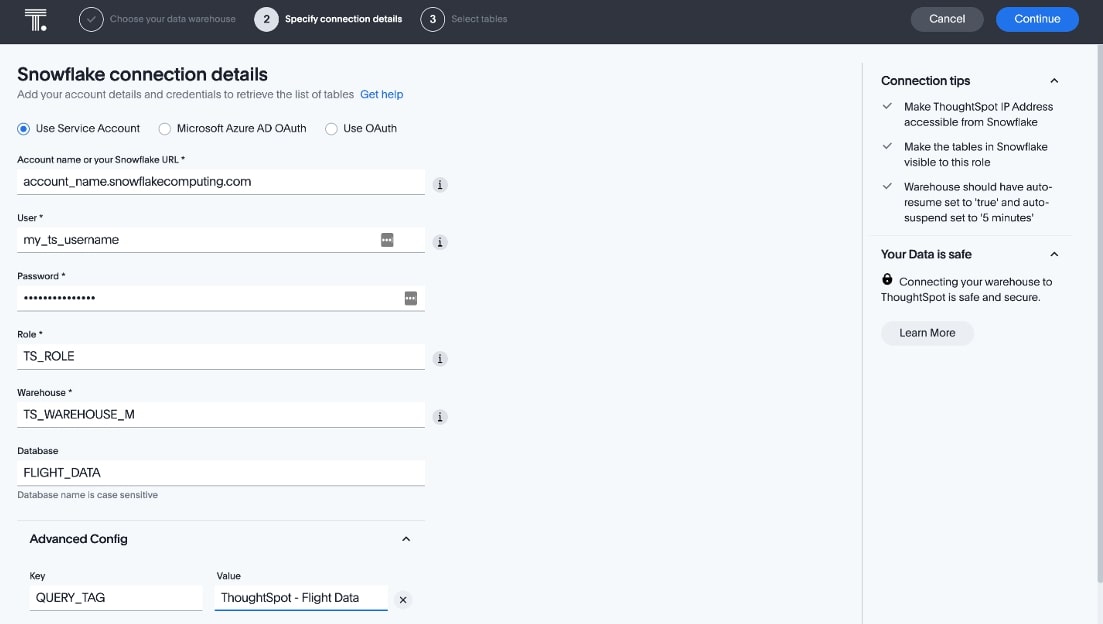
Step 2: Configure the connection
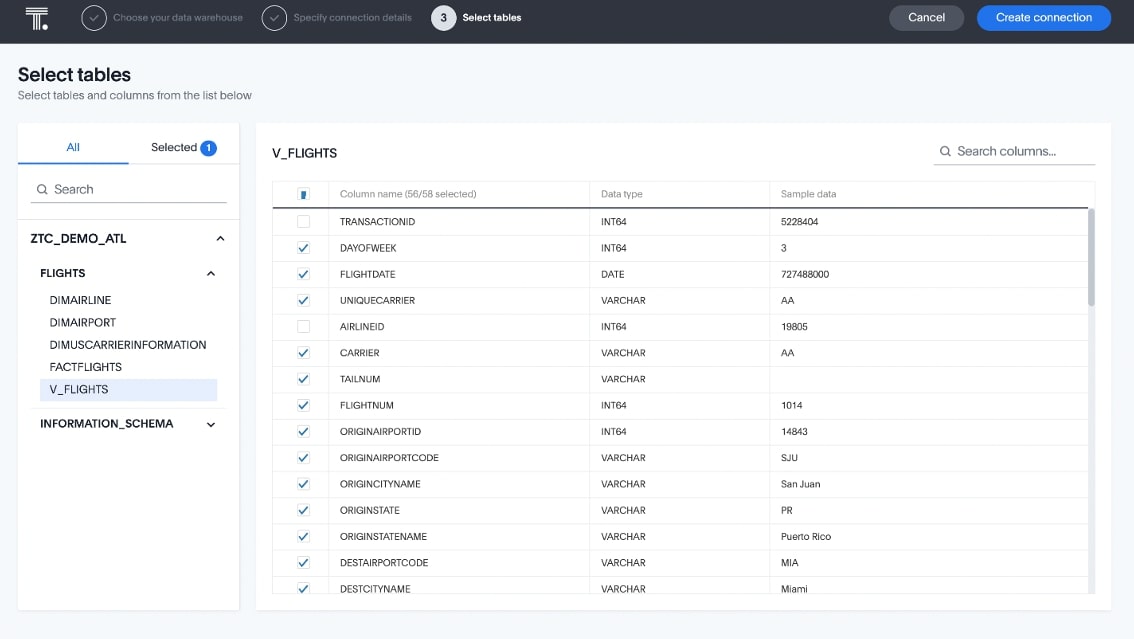
Step 3: Add objects from that connection
Once you’re done adding your objects, in cloud or on-prem, ThoughtSpot creates tables in the data section of your ThoughtSpot environment. Users can run searches on tables, but it is best practices to create worksheets and views for searches. Similar to the content hierarchy, there is a data hierarchy within ThoughtSpot, too.
Data Hierarchy in ThoughtSpot
Tables are the base data objects in ThoughtSpot. Tables are currently tables, views and materialized views in the data source, and custom SQL is on the roadmap for ThoughtSpot. Row-Level security (which is the subject of my next blog) is applied at the table level, and tables can be joined to each other within the ThoughtSpot data model.
Worksheets are the most commonly used objects in ThoughtSpot search. Worksheets are built upon tables and can be a subset of the columns within ThoughtSpot. This allows for a robust metadata layer and enables organizations to manage multiple views of the same data object within ThoughtSpot. Many BI toolsets require a lot of extra work, or it’s just not possible to reuse a table or a base data object.
Worksheets also allow for user-defined calculations and aggregations, as well as different synonyms. For example, maybe one department calls a field sales_ty as Sales while another calls it Current Year Revenue. Worksheets can be configured for different organizations with synonyms and appropriate level aggregations for their needs. Worksheets can also be joined to each other and other table objects and views as needed. The data modeling is quite robust (next blog entry) in ThoughtSpot. For the cloud offering, ThoughtSpot queries are executed against the cloud data platform in real time.
Views in ThoughtSpot
The final layer in ThoughtSpot’s data architecture is views. Views are very useful when you’ve created an answer on which you want to perform an additional search. Let’s say your answer is the Top 10 On-time Destination Cities of flights out of Atlanta. From there, you want to further search that dataset. In this case, you would create a view. ThoughtSpot materializes this dataset in memory to allow for joins, additional searches and answers. For the more SQL experienced, another way to think of this is nested SQL. Let’s look at a specific example.
First, I search for Top 10 Destination Airport codes filtered to Atlanta as the origin city and make sure I’ve got Ontime% on the view, too:
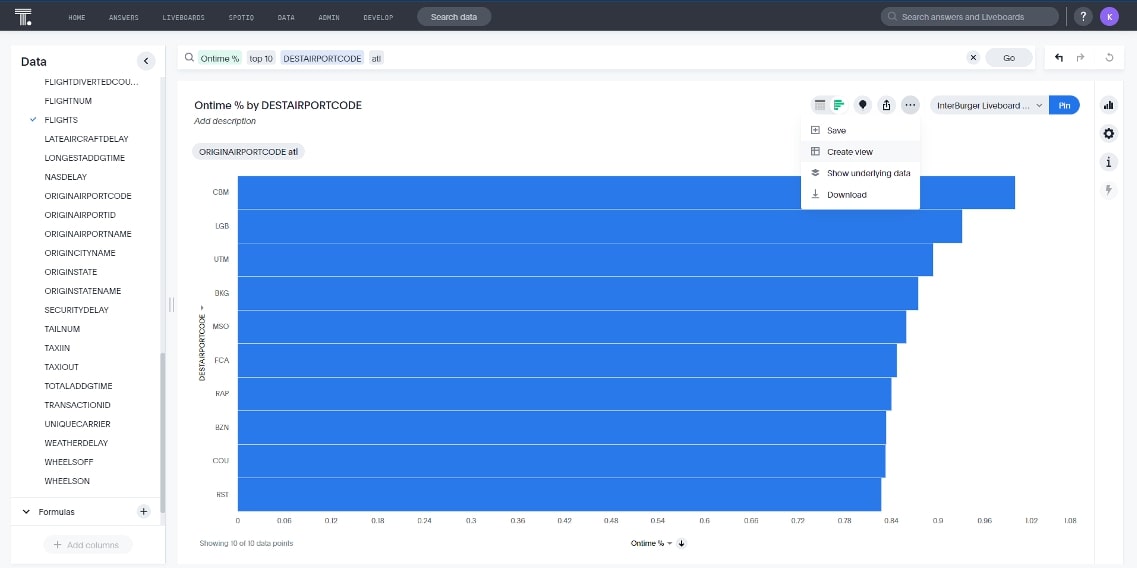
Second, I save the view:
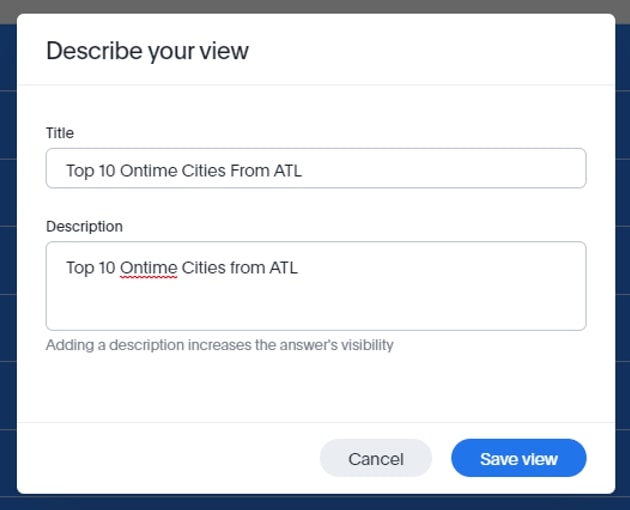
Next, I join this to the original table by going to the view and adding a Join on DESTAIRPORTCODE:
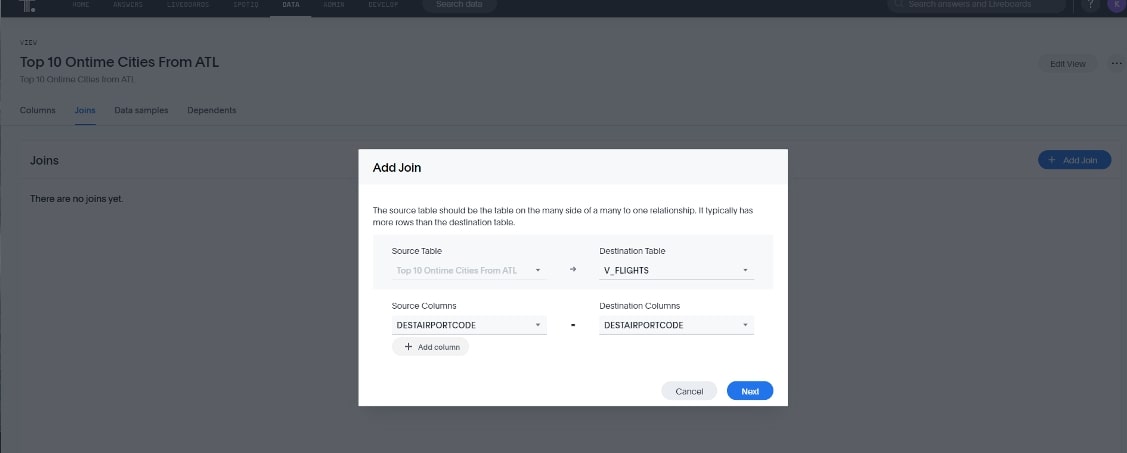
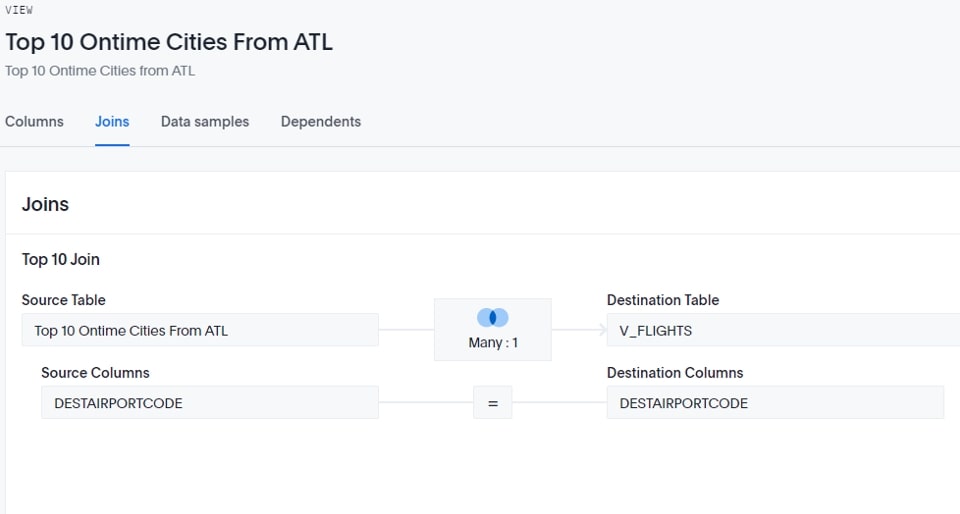
Lastly, I add both objects to my search and I can now do searches using this subset for my results:
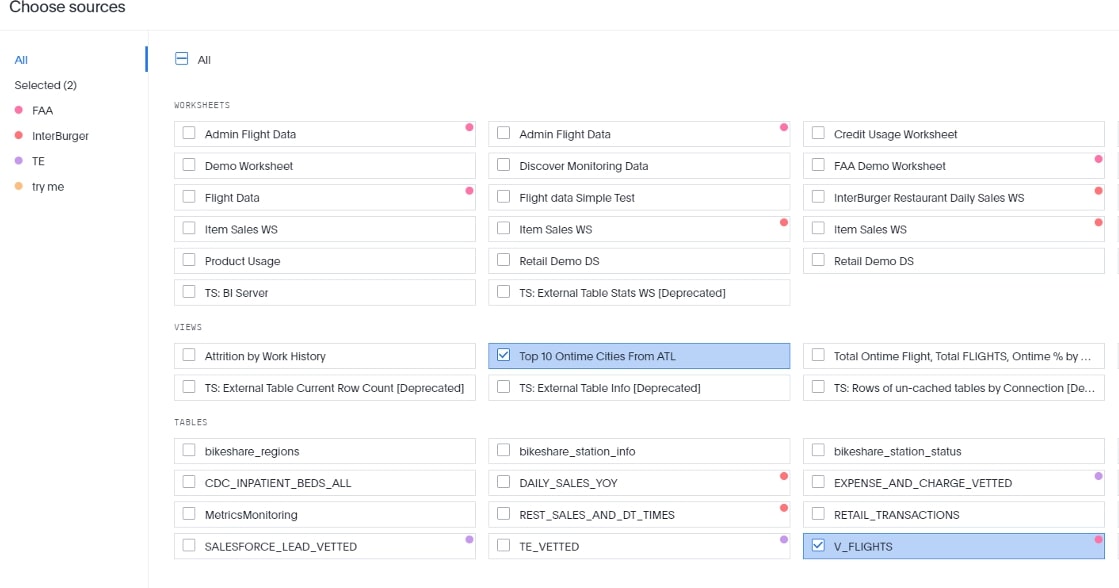
And the subsequent search:
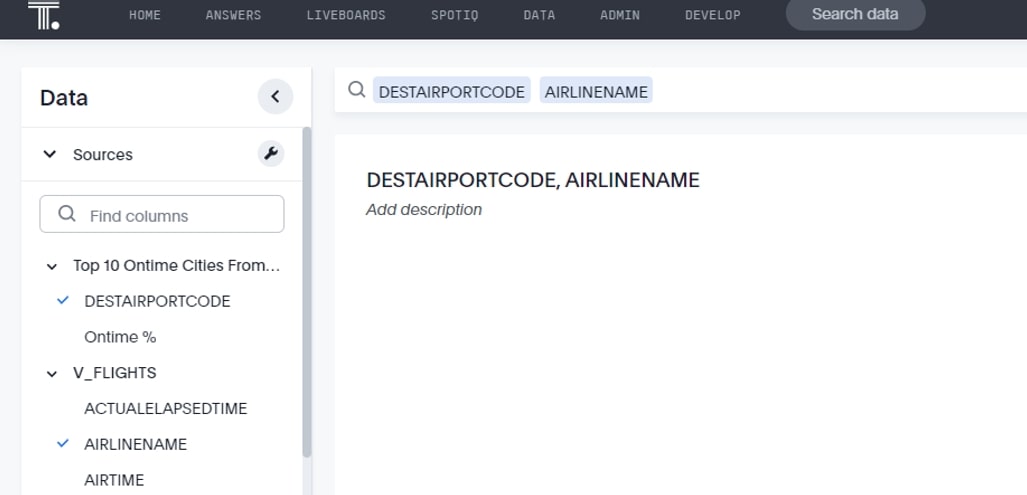
Notice both tables’ columns are being used here.
Views save development time, too. In the past, we would normally have to think about this ahead of time and model the data to accomplish this. It may be the right thing in the long term to model out an object in the database for this, but data engineering time is valuable, and the pace of business is generally faster than the pace of data modeling, so ThoughtSpot allows for this on demand to get to the right answer faster. Then we can model this out if it is indeed needed repeatedly.
Want More ThoughtSpot?
If you want to engage in a deeper conversation about ThoughtSpot, we would love to talk to you! Please reach out. And be looking for our next blog on modeling and managing data for ThoughtSpot. We’ll dive into row-level security, ThoughtSpot Modeling Language (TML) and data management.