
A few weeks ago, I wrote about the wonderful world of graph theory and graph databases. In doing so, I touched briefly on some of the practical uses of graphs. I would like to expand on this by looking at a specific use case: recommendations.
We see recommendation systems everywhere, from Amazon’s suggestions, targeted advertisements on Facebook and everywhere in between. Each recommendation system is different. Because of this, there are a number of ways to go about creating such a system. Data science, being the great buzzword that it is, has taught us that there’s an algorithm for this problem. In fact, there are many. But, this isn’t the only approach we can take. Here, I will present an alternative to the algorithmic approach by using the structure of our graph.
By using a graph database like Neo4j (which we will use here), we can simply traverse paths in our graph to make recommendations. This alternative has an advantage in that traversing paths in a graph database is much more efficient (on the order of milliseconds) than having to run an algorithm (which often requires data prep and comes with variable execution time from millisecond to minutes). This advantage means that this system can be embedded in an environment that requires real-time results with little to no additional prep. With that said, let’s build our graph model.
The Data
Creating a hypothetical graph model requires a bit of time and consideration, but the graph model I decided on consists of the following: a small social network of ten people, each giving ratings on several restaurants in the city of Stillwater, OK (thirteen restaurants are present in the graph model).
Another addition I made to the graph was the notion of classifying restaurants by the type of food served there. These are represented by the wickedly creative node label of TYPE. Below are sub-graphs to show the network structure that we will be working with. Note that the colored nodes each represent a different type of node:
- Purple = people
- Orange = restaurants
- Blue = restaurant type
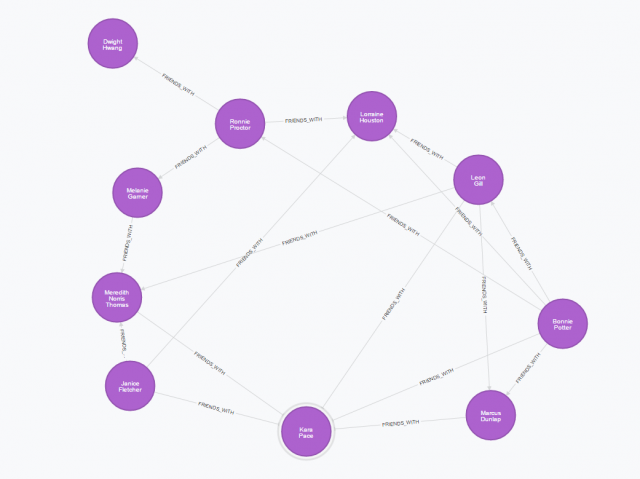
Above: The social network.
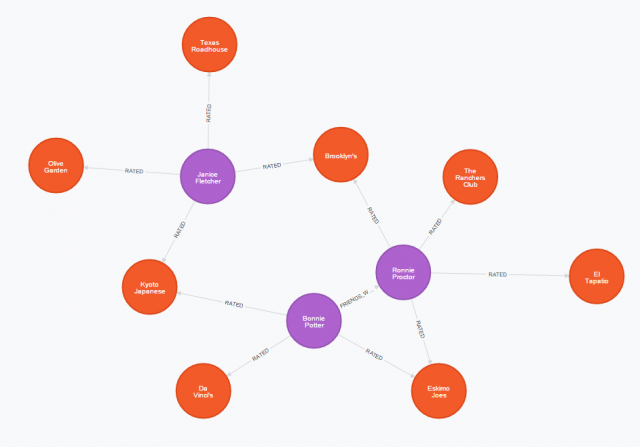
Above: Restaurant ratings by friends.
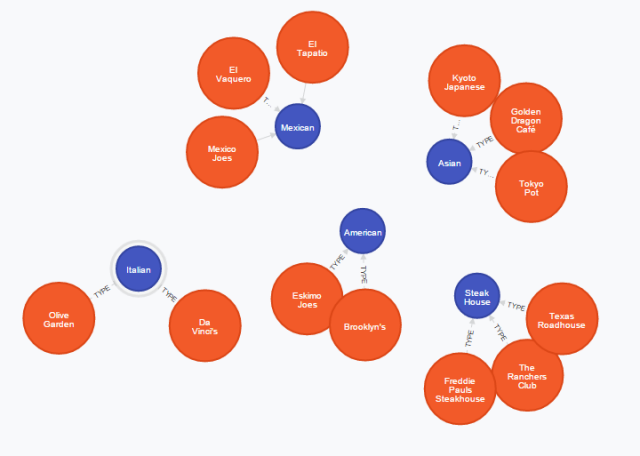
Above: Types of food served at each restaurant.
Making Recommendations
With the graph model set, we can start to think about the reasoning behind the recommendations we want to make. We will go through three lines of reasoning here.
Recommendations Based on Restaurant Type
If a person highly rates an Italian restaurant (or several), chances are that the person enjoys Italian food. Therefore, it would make sense to recommend more Italian restaurants. If we wanted to make recommendations based on the type of restaurants that have been rated highly, then we simply need to determine the path we are interested in traversing. In this case we are interested in finding all the types of restaurants a person has rated. This pattern looks like (note that this is a pseudo-query):
(person) – [:RATED] -> (restaurant) – [:TYPE] -> (restaurant type)
From here, we want to find all the restaurants with that type. To do this, we simply expand our pattern as follows:
(person) – [:RATED] -> (restaurant) – [:TYPE] -> (restaurant type) <- [:TYPE] – (restaurant)
Great, we have all the restaurants in the graph that match the type of restaurants this person has rated.
We now need to determine which restaurants this person has not rated yet (we assume that the person is adventurous and would like to try something new). Also, to limit our recommendations to restaurant types that this person actually enjoys, we will impose the condition that the ratings given must be at least a 3. Below is the query that we pass to our graph database and the resulting list of recommendations for every person in our database.
Query:

Results:
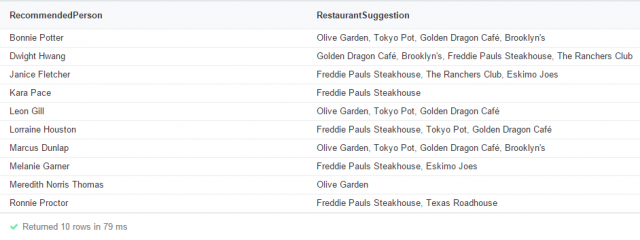
Recommendations Based on Common Ratings
Another line of reasoning we can follow is: If two people rate the same restaurants highly, then their tastes are more likely be similar. Using this, can we find people who have given similar ratings to the same restaurants and make recommendations based on this information? Let’s find out.
First, let’s start by finding all the people who have rated the same restaurants. This can be accomplished by finding the paths that start from one person and lead to another by traversing through a restaurant node. In other words, we want a path that looks like:
(person1) – [:RATED] -> (restaurant) <- [:RATED] – (person2)
Great, now we have all the people that have rated the same restaurants, but we cannot make new recommendations with this pattern. We need to find restaurants that have yet to be rated by person1. To do this, we must add a separate restaurant node to the path. We do this below:
(person1) – [:RATED] -> (restaurant1) <- [:RATED] – (person2) – [:RATED] -> (restaurant2)
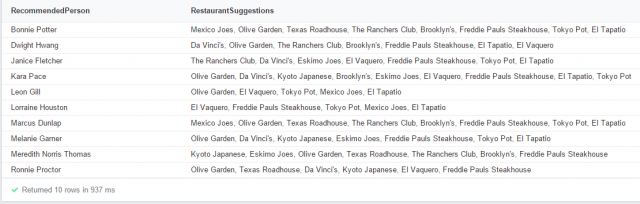
This isn’t quite good enough. From here, we see that there is no guarantee that person1 hasn’t already rated restaurant2. To ensure that this doesn’t occur, we simply add this condition to our query (see image below). From here, we simply add the condition that the first rating must be at least a 3 to be considered for a recommendation. As before, the query and the resulting set of recommendations for each person in the graph are below.
Query:

Results:
Recommendations Based on Friends’ Ratings
Now, let’s explore a principle that we are probably very familiar with. Typically, we are very similar to our friends. Our similarities are usually what we build our friendships around. With this in mind, perhaps we would like to add friendship recommendations to our list. It just so happens that we have a social network in our graph. Let’s see how we can leverage this to make recommendations.
We start by first finding all the friends a person has. The pattern that we are looking for looks like:
(person1) – [:FRIENDS_WITH] – (person2)
That was simple enough, but there’s something interesting that I omitted. In Neo4j, all relationships are directed from one node to the next. To avoid complexity in our graph, I opted to have one edge connect a pair of friends. Hence, our relationships go from one person to the next and not in the reverse. I chose to do this for two reasons:
- To make my life simple. I created the data set by hand and didn’t want to make redundant relationships.
- There is no need to have directions going both ways in a social network. This is because Neo4j allows traversals in either direction when we are querying our graph. Understanding that we will need to traverse some paths in the reverse direction, we omit the direction in the above pattern.
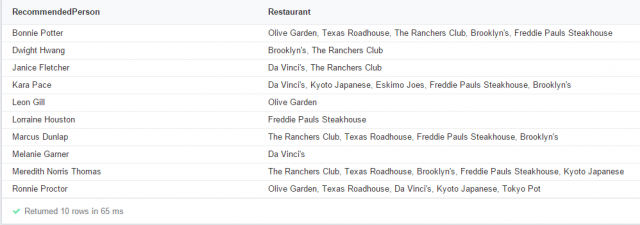
As in the previous two cases, we expand this pattern to include restaurants that our friends have rated. This imposes the condition that their ratings must have been at least a 3. Below are the query and the resulting recommendations.
Query:

Results:
Conclusion
Here, we have shown how to make recommendations on a graph by using path traversals to find predetermined patterns. Admittedly, this is a simple solution to a potentially complex problem. These ideas are at the core of recommendation systems that we are all familiar with. These include Facebook suggested friends (using the idea of triadic closure), Pandora radio and the suggestions of what music channels you might enjoy, etc.
If these solutions are too simple for you, we have options for how we could improve our recommendations. Perhaps we can combine two or more of these queries to make even more meaningful and robust recommendations. Additionally, we could add structure to the graph that perhaps isn’t currently present.
All in all, graphs provide quite a simple yet elegant solution to a problem where there are plenty of potentially complex algorithms that can solve the same problem in more time. This is one example where we can easily leverage the power of graphs.