
In a previous installment, we kicked off this blog series by materializing our policy and entitlement table and removing all physical joins in our data source. We are now left with a large volume of records due to combining users with what they’re entitled to. To address this growth, we need to profile our materialized table to determine homogeneity. The more homogenous our records, the greater effect distillation would have in reducing table and workbook size. Note: Distillation isn’t necessarily required if we have a small number of users with security at non-granular levels (e.g. thousands of users secured by geography). In the following example, we’ve determined our materialized example to be largely homogeneous (61%) despite thousands of users secured by Order ID. This is due to a large proportion of users having global access to all Order IDs:
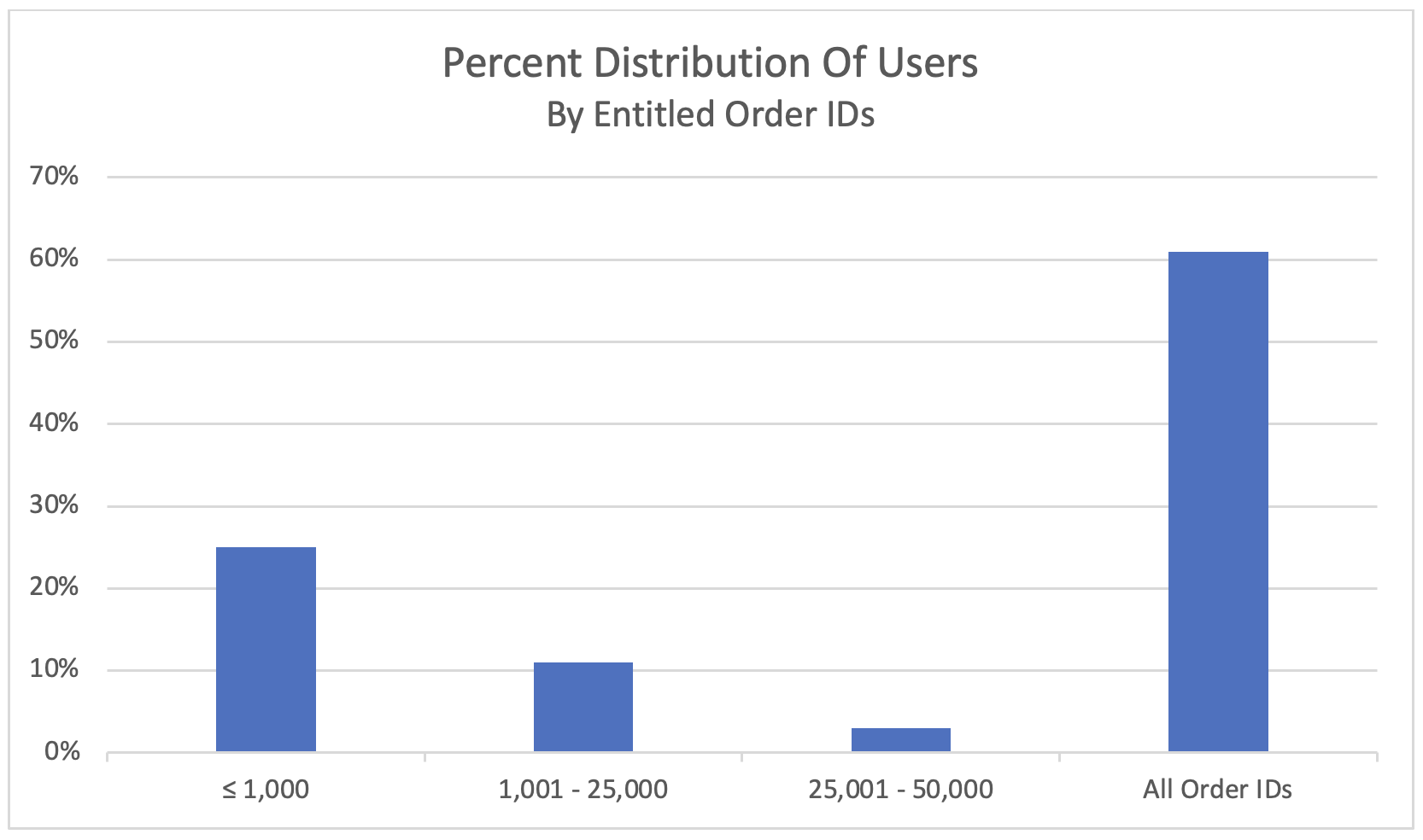 Figure 3: Percent Distribution Of Users By Entitled Order IDs
Figure 3: Percent Distribution Of Users By Entitled Order IDs
Distillation
In the example above, 61% of our 100,000 users have global access to Order IDs. There exists 50,000 unique Orders IDs globally. Security is by region, with Order IDs split between 3 regions: Americas, Europe and Asia. Thus, global users account for over 3 billion records (.61 * 100,000 * 50,000) in our materialized table! Rather than storing these records as-is, we can distill global user records by region as shown:
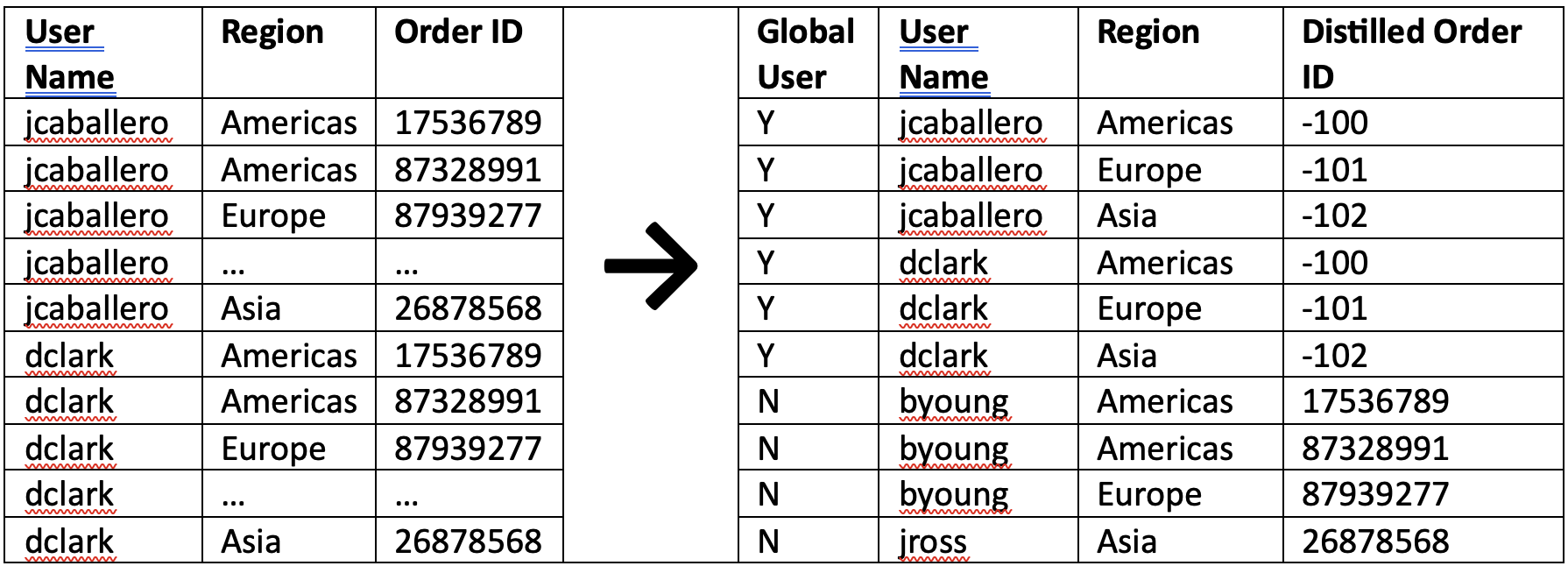
Figure 4: Distilled Orders + Entitlement
As a result of distillation, global users would then account for only 183,000 records (.61 * 100,000 * 50,000), a far cry from over 3 billion records previously! The remaining non-global users would be left as-is since they are non-homogenous. However, we would need a lookup table to translate our distilled Order IDs into their actual Order IDs. In Part 3 of our series, we’ll cover methods for translation as a result of distillation and continue to build optimal data models. Stay tuned!