
From its inception, Snowflake has always supported the ANSI standard version of the SQL language. As much as we may enjoy using SQL to manipulate data – how cool is it to write in a language based on something called lambda calculus? Still, it doesn’t quite work when it comes time to write some procedural commands, stepping from one to command to another, particularly in stored procedures.
Snowflake SQL allows for stored procedures, certainly, but we have had to define them in another language such as JavaScript. (Admittedly, the list of languages to write stored procedures has been growing and we can also now write stored procedures in Python, Java, and Scala.) This was useful, but issuing even the simplest SQL command was often clunky and time-consuming.
No more.
Since its general release in April, Snowflake has allowed for Stored Procedures to be written in a near-SQL dialect called “Snowflake Scripting.” This scripting language fits seamlessly with SQL commands and is extended to allow for procedural, conditional and error-handling statements.
We will attempt to illustrate some of the main features of Snowflake Scripting through example stored procedures. Let’s start with something simple.
Based on What We Already Know
Snowflake Scripting is a simple extension to the SQL language we already know, gently surrounding commands with a BEGIN-END pair. For our first example, we want to have a quick way to delete a small number of temporary tables that we know the names of.
-- drop my specific list of tables CREATE OR REPLACE PROCEDURE drop_tmp_tables() RETURNS TEXT LANGUAGE SQL EXECUTE AS CALLER AS BEGIN DROP TABLE "tmp_CUSTOMER"; DROP TABLE "tmp_SALES_ITEM"; DROP TABLE "tmp_PRODUCTS"; RETURN 'Success'; END; --sample call of the procedure -- CALL drop_tmp_tables();
Note: The indentation isn’t required, but it helps readability.
It’s worth noting that the above works in the newer web interfaces for Snowflake (SnowSight or SnowPark), but for the Classic web interface or SnowSQL (i.e., the command line interface) we need to achieve the same thing by putting the executable commands into a string.
-- again, drop my specific list of tables, delimited with $$
CREATE OR REPLACE PROCEDURE drop_tmp_tables()
RETURNS TEXT
LANGUAGE SQL
EXECUTE AS CALLER
AS $$
BEGIN
DROP TABLE "tmp_CUSTOMER";
DROP TABLE "tmp_SALES_ITEM";
DROP TABLE "tmp_PRODUCTS";
RETURN 'Success';
END;
$$;
The $$ delimiters act as the begin-end markers for a multi-line string. This includes the string-within-a-string being returned to indicate success. We’ll use this form going forward, since it is a simple matter to convert it back to the unquoted version. And, in fact, this $$-form also works within the newer interfaces.
Variables for Flexibility
Snowflake Scripting allows for variables to hold temporary values within the stored procedure, including values passed in as a parameter. In our next example, we pass in such a parameter and use it to make copies (clones) of our three tables; these tables will be named with the passed-in prefix.
-- create clones of my list of tables, with a specified prefix
CREATE OR REPLACE PROCEDURE clone_my_tables(prefix_str TEXT)
RETURNS TEXT LANGUAGE SQL EXECUTE AS CALLER
AS $$
DECLARE
t1 TEXT default 'CUSTOMER';
t2 TEXT default 'SALES_ITEM';
t3 TEXT default 'PRODUCTS';
newname TEXT;
BEGIN
newname := '"' || prefix_str || t1 || '"';
CREATE OR REPLACE TABLE IDENTIFIER(:newname) CLONE IDENTIFIER(:t1);
newname := '"' || prefix_str || t2 || '"';
CREATE OR REPLACE TABLE IDENTIFIER(:newname) CLONE IDENTIFIER(:t2);
newname := '"' || prefix_str || t2 || '"';
CREATE OR REPLACE TABLE IDENTIFIER(:newname) CLONE IDENTIFIER(:t3);
RETURN 'Success';
END; $$;
In this simple example, you can see a few more of the capabilities of Snowflake Scripting. Specifically, we are able to:
- Define the variables in the DECLARE section before the BEGIN.
- Update the “newname” variable for each table by prepending the prefix.
- Issue the “CREATE TABLE” command to clone the newly-named table from the old table.
The “IDENTIFIER()” function allows us to use the “TEXT” variables within the command to specify the table names. Note that within the SQL command, we name the variables with a colon in front, such as “:t1.” However, the colon is not necessary when assigning or reading from the variables, as in the line before the SQL command. We’ve tried to be consistent throughout when declaring variable types and so we use “TEXT” because it is short; it is synonymous with “STRING” or “VARCHAR,” etc.
It’s worth mentioning that the Snowflake SQL command “EXECUTE IMMEDIATE <string>” can be used to great effect within Snowflake Scripting. This command executes the SQL statement contained within the string given to it, which is handy since that string can be built on-the-fly.
-- create clones of my list of tables, with a specified prefix, v2
CREATE OR REPLACE PROCEDURE clone_my_tables2(prefix_str TEXT)
RETURNS TEXT
LANGUAGE SQL
EXECUTE AS CALLER
AS $$
DECLARE
cmd1 TEXT default 'CREATE OR REPLACE TABLE "';
cmd2 TEXT default '" CLONE ';
t1 TEXT default 'CUSTOMER';
t2 TEXT default 'SALES_ITEM';
t3 TEXT default 'PRODUCTS';
newcmd TEXT;
BEGIN
newcmd := cmd1 || prefix_str || t1 || cmd2 || t1;
EXECUTE IMMEDIATE newcmd;
newcmd := cmd1 || prefix_str || t2 || cmd2 || t2;
EXECUTE IMMEDIATE newcmd;
newcmd := cmd1 || prefix_str || t3 || cmd2 || t3;
EXECUTE IMMEDIATE newcmd;
RETURN 'Success';
END;
$$;
Building a string is a straightforward way to use the “EXECUTE IMMEDIATE <string>” command. You can also create commands with placeholders for the changeable values (the placeholders are simple question-marks: “?”), and then pass in variables in the “USING” form of the command:
EXECUTE IMMEDIATE <string-with-placeholders> USING (<variable1>, <variable2>,...)
We’ll see how to use this second form in the examples below.
Looping Over Results
We’ve used only string variables so far, but variables can be any data type that Snowflake supports, e.g., “NUMERIC,” “FLOAT,” “ARRAY,” “OBJECT,” etc. In addition, you can capture the result of a SQL command in a variable of type “RESULTSET,” and then the magic really begins. The “FOR-loop” of Snowflake Scripting enables you to loop over each row of such a “RESULTSET,” that is addressing each row from the query.
FOR my_variable IN <result_set> DO -- Statements to execute for each row in the result_set -- refer to column values via my_variable.column_name END FOR;
As an example, let’s expand on our previous stored procedure and provide a way to drop any table whose name starts with any prefix. We can query a list of all the tables that start with the prefix, and then we can loop through the results and drop each table one-by-one within the FOR-loop.
-- drop tables in this schema that have a given prefix
CREATE OR REPLACE PROCEDURE drop_tables_starting_with(prefix_str TEXT)
RETURNS TABLE()
LANGUAGE SQL
EXECUTE AS CALLER
AS $$
DECLARE
tbl_query TEXT default 'SELECT table_name FROM information_schema.tables ' ||
'WHERE table_type = ''BASE TABLE'' AND table_schema = CURRENT_SCHEMA() ' ||
'AND STARTSWITH(table_name, ?)';
drop_cmd TEXT default 'DROP TABLE IDENTIFIER(?)';
rs RESULTSET;
tmp TEXT;
BEGIN
rs := (EXECUTE IMMEDIATE tbl_query USING (prefix_str)); ①
FOR tbl_row IN rs DO ②
tmp := '"' || tbl_row.table_name || '"'; ③
EXECUTE IMMEDIATE drop_cmd using(tmp); ④
END FOR;
RETURN TABLE(rs); ⑤
END;
$$;
-- sample call of the procedure
-- CALL drop_tables_starting_with('tmp_');
Looking at the procedure, we see a couple of strings declared (tbl_query and drop_cmd) which contain SQL-commands with “?” placeholders. For the body of the procedure, we perform the following:
- Use “EXECUTE IMMEDIATE” to get the tables that we want by querying from the “INFORMATION_SCHEMA.TABLES” view (the prefix string is passed in with the “USING” statement), and assign the result to the “RESULTSET” variable “rs.”
- Loop over the “RESULTSET” in a FOR-loop (each row being pointed at by the “tbl_row” variable).
- Carefully build a double-quoted version of the table name (which is accessed with “tbl_row.table_name.”)
- Use “EXECUTE IMMEDIATE” to drop the table “USING” this table name.
- Return the query result (as a “TABLE”) to indicate which tables were dropped.
There are other forms of looping in Snowflake scripting, including “WHILE-loops,” “REPEAT-UNTIL-loops,” “counter-based FOR-loops,” and even unending “LOOPs” (well, not unending – you should use a “BREAK” to jump out of such a loop eventually.) For a quick comparison of these different styles, see the footnote to this blog.
A couple more features of Snowflake scripting will round out the examples in this introduction.
Conditions and Exceptions
When working in a procedural language, the commands being executed are often dependent upon some condition or another. The simple “IF-THEN” statement can be used in Snowflake scripting to provide such conditional execution. Additional variations allow for “IF-THEN-ELSE” and a cascading condition with “IF-THEN-ELSEIF-ELSE,” as follows:
IF (<condition>) THEN -- Statements to execute if the <condition> is true. [ ELSEIF (<condition_2>) THEN -- Statements to execute if the <condition_2> is true. ] [ ELSE -- Statements to execute if none of the conditions is true. ] END IF;
Now, when executing statements in a stored procedure, sometimes not everything goes as planned. When those unfortunate times occur, an error can be intercepted before being passed back to the caller by using an “EXCEPTION” clause. These clauses come at the end of the “BEGIN-END” block, or rather, just before the “END” statement. Within an “EXCEPTION” clause, you can test for the type of exception that has occurred and handle it accordingly. Snowflake has two built-in error types: “statement_error” for when SQL statements fail and “expression_error” when expressions are not able to be processed; you can also define your own error type (which we won’t get into).
BEGIN -- Statements to execute EXCEPTION WHEN <error_type> THEN -- Statements to execute to clean up after error. END;
Consider the following stored procedure which will rename all column names to be completely upper-cased (I’ve found this procedure useful after a source file is loaded with lots of mixed-case column names). Before issuing a “RENAME,” it uses an “IF-THEN” to see if a column needs changing and it will handle and report on any statement error that may be encountered.
-- Procedure UPPER_COLNAMES(tbl_name)
-- Description: Change the column names of a table to uppercase
-- Parameters: tbl_name - the name of the table whose
-- columns will change
-- Returns: Object describing the result of the operation
-- ('RESULT' key contains SUCCESS or other error message)
-- Example: call upper_colnames('my_schema.my_table');
CREATE OR REPLACE PROCEDURE upper_colnames(tbl_name text)
RETURNS OBJECT
LANGUAGE SQL
EXECUTE AS CALLER
AS $$
DECLARE
describe_cmd TEXT default 'DESCRIBE TABLE IDENTIFIER(?)';
rename_cmd TEXT default 'ALTER TABLE IDENTIFIER(?) ' ||
'RENAME COLUMN IDENTIFIER(?) TO IDENTIFIER(?)';
success_result OBJECT default object_construct('RESULT', 'SUCCESS');
rs RESULTSET;
BEGIN
-- execute a DESCRIBE TABLE command
rs := (EXECUTE IMMEDIATE describe_cmd using (tbl_name) ); ①
-- for each column in the result,
-- change the column name to UPPERCASE if it's not already)
-- by issuing an ALTER TABLE – RENAME COLUMN command
FOR col_desc IN rs DO ②
IF (col_desc."name" != upper(col_desc."name")) THEN ③
LET old_name TEXT := '"'|| col_desc."name"||'"'; ④
LET new_name TEXT := '"'||upper(col_desc."name")||'"';
EXECUTE IMMEDIATE :rename_cmd USING (tbl_name,old_name,new_name); ⑤
END IF;
END FOR;
RETURN success_result; ⑥
EXCEPTION ⑦
WHEN statement_error THEN
RETURN object_construct('RESULT', 'STATEMENT_ERROR',
'SQLCODE', sqlcode,
'SQLERRM', sqlerrm,
'SQLSTATE', sqlstate);
END;
$$;
Let’s look at this procedure and break it down. We once again see a couple of “TEXT” strings declared which contain SQL commands with “?”-mark placeholders. These commands will allow us to describe the table we’re interested in and rename the columns as needed. In the body of the procedure, we perform the following:
- Get a description of the table (via “EXECUTE IMMEDIATE” and “USING” the table name passed in) and assign the result to the “RESULTSET” variable “rs.”
- Loop over the “RESULTSET” in a FOR-loop (each row is a column description, and is pointed at by the “col_desc” variable).
- Use “IF-THEN” to check if the column name needs to be changed to upper-case.
- If it does need to be changed, carefully build the double-quoted names for renaming.
- Notice we’re using some variables that weren’t declared in the “DECLARE” section. We use a shortcut within the “BEGIN-END” block for declaring variables as we need them.
-
LET <variable_name> <type> := <expression> ;
- Use “EXECUTE IMMEDIATE” to rename the columns “USING” the table name, the old column name, and the new column name.
- When all goes well, we return an object that indicates a successful result.
- Should a statement error occur, it will be caught and an appropriate object returned describing the error.
Great Power and Responsibility
The extensions to standard SQL that Snowflake Scripting brings are very powerful and very convenient. Understand that I love standard procedural languages as much as anyone, and I’m grateful for the extended power they bring to SQL statements. However, there are a few warnings that come with this increased power. The warnings are applicable to stored procedures written in any language, and are particularly worth remembering with Snowflake Scripting:
Don’t Give Up Your OWNER-ship
All of the example stored procedures have a property in common: “EXECUTE AS CALLER.” This is intentional, and reflects the best practice in stored procedures of preserving the rights of the caller throughout the procedure. In this way, the caller cannot perform any function with a procedure that she couldn’t also perform just by listing SQL commands.
When a stored procedure has the property “EXECUTE AS OWNER,” there is the potential to lend more rights and power to the commands being executed in the procedure than was intended. For example, if a stored procedure were created by “SYSADMIN,” and called by some lesser role, it might allow for tables to be accessed, altered or even dropped that normally the lesser role could not touch. With our procedure “drop_tables_starting_with,” for example, it would be possible to drop tables not owned by (or granted access to) the caller.
That being said, there are several use cases where “EXECUTE AS OWNER” is useful or even needful to carry out the proper operation of a procedure. Creation of such stored procedures must be made with extra caution in such cases. In my opinion, however, the “EXECUTE AS CALLER” property should be the default (although, unfortunately, this is not the case – Snowflake will assume “EXECUTE AS OWNER” if you do not specify otherwise).
Beware of SQL Injection
Although not strictly a part of Snowflake Scripting, the Snowflake SQL command “EXECUTE IMMEDIATE” is often used to great effect within stored procedures. When command strings are cobbled together from user input, sneaky callers can alter a simple command and potentially change it to perform very different functions. This kind of deception is called SQL Injection and can lead to major problems.
Let’s inspect an example of a useful, but potentially dangerous stored procedure. This procedure will execute any command given to it (such as “DESCRIBE TABLE my_table” or “SHOW ROLES”), and place the results into a table.
CREATE OR REPLACE PROCEDURE command_to_table(command TEXT, table_name TEXT)
RETURNS TEXT
LANGUAGE SQL
EXECUTE AS CALLER
AS $$
BEGIN
IF (length(TRIM(command)) = 0) THEN RETURN
('Parameter Error: command to be executed (parameter 1) must be non-empty');
ELSEIF (length(trim(table_name)) = 0) THEN RETURN
('Parameter Error: table name for results (parameter 2) must be non-empty');
END IF;
EXECUTE IMMEDIATE :command;
CREATE OR REPLACE TABLE IDENTIFIER(:table_name) AS
SELECT * FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()));
return 'Success: table '||table_name||' created.';
EXCEPTION
when statement_error then
return 'Statement error: '||sqlerrm;
when other then
return 'Error: '||sqlerrm;
END;
$$;
This procedure starts off well by illustrating the good practice of pre-flighting inputs: it first checks the parameter strings given to it and makes sure they are not empty. After that, it executes the command passed in and then creates the output table with a “CTAS” (Create Table As Select) command — it uses the “RESULT_SCAN” and the “LAST_QUERY_ID” in that Select-query to get the output. It works great for things like the following:
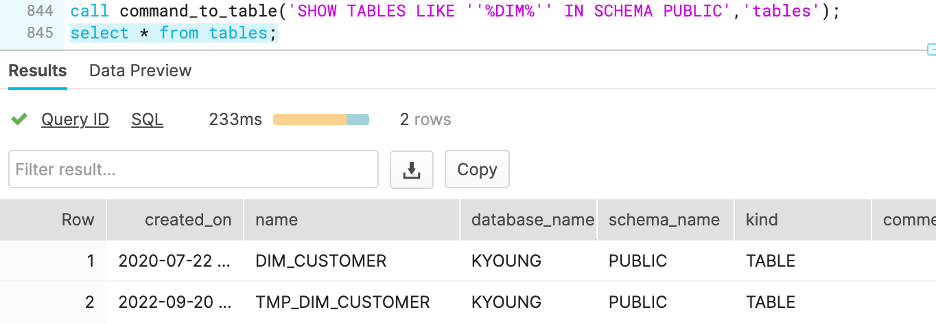
CALL command_to_table('SHOW TABLES LIKE ''%DIM%'' IN SCHEMA PUBLIC','tables');
With this call it would create a table in the current schema with a list of dimension tables from “PUBLIC,” as shown below.
But what if the caller got creative with the string that was to be passed to this command?
SET tmp = 'BEGIN DROP TABLE MY_SCHEMA.FACT_MAIN; ' ||
'DROP TABLE MY_SCHEMA.FACT_EMPLOYEES; END';
CALL command_to_table($tmp, 'blank');
Trickery! Trickery! Now the friendly “command_to_table” procedure turns into something potentially destructive – dropping important tables, as in xkcd’s ‘Bobby Tables’ web comic,, and hiding its tracks with an empty table named “BLANK.” If the procedure had been defined with “EXECUTE AS OWNER,” it could have been potentially even more dangerous.
Technically, the example above isn’t SQL Injection, but rather an exploit taking advantage of an open execution of a string. In general, the “EXECUTE IMMEDIATE” command can be prevented from suffering from SQL Injection – especially with the “USING” form of the command – but it is still worth being aware of the potential abuse of input commands.
Don’t Get Lost in a Procedural Rabbit Hole
You may have noticed that all of the example stored procedures we’ve shown have been mostly concerned with doing things that affect data structure – dropping and creating tables, showing meta-information, updating column names, etc. This is the Data Definition Language side of SQL (DDL), which can be contrasted with the Data Manipulation Language (DML) side, the querying, selection and relational joins. This is not to say that DML cannot be used in Snowflake Scripting, it certainly can (and we did use it where appropriate).
The fact is that SQL is already tailor-made for data manipulation, so there is less need for procedural assists on the DML-side of things. Imagine how sad (not to mention inefficient) it would be to try to update or filter columns in a FOR-loop when we already have the UPDATE command and the WHERE clause. Still, the ability to line up a series of queries, table updates and inserts can be a key component of a data pipeline.
Use It For Good
Snowflake Scripting is a very useful and efficient way to set up your procedures in in Snowflake. Because of its close integration with SQL, it can be a clear, clean and your new best friend.
Footnote — Lots of LOOPs
As mentioned, there are other ways to perform loops in Snowflake Scripting. We will try to look at the different styles and compare their relative efficiency.
FOR-loop with a counter
The most classic type of loop in procedural languages, the FOR-loop, involves counting up or down with a variable a set number of times.
FOR <counter_variable> IN [REVERSE] <start> TO <end> DO -- Statements to execute for each value of the counter variable END FOR;
For our testing, we run through this style of FOR-loop a million times, doing as little as is reasonable within the loop, and look at the execution time:
BEGIN
LET tmp NUMBER := 0;
FOR counter_variable IN 1 TO 1000000 DO
tmp := counter_variable;
END FOR;
END;
This took 30.1 seconds, indicating about 30 microseconds per loop.
FOR-loop across a RESULTSET
Another type of FOR-loop involves looping across the results of a query; this is the type of loop that we discussed earlier.
FOR my_variable IN <result_set> DO -- Statements to execute for each row in the result_set -- refer to column values via my_variable.column_name END FOR;
For our testing, we used a “GENERATE” query to get a million rows to loop across, and looked at the execution time:
BEGIN
LET tmp NUMBER := 0;
LET rs RESULTSET := (SELECT SEQ8() num
FROM TABLE(GENERATOR(ROWCOUNT => 1000000)));
FOR counter_variable IN rs DO
tmp := counter_variable;
END FOR;
END;
This took 20.8 seconds, which the initial query took 0.7 seconds of. This seems to indicate only 20 microseconds per loop. This is remarkably efficient, even if the initial query’s time were factored in.
WHILE-loop
A WHILE-loop will continue to loop as long as the condition remains true.
WHILE (<condition>) DO -- Statements to execute while the condition is true END DO;
For our testing, we simply loop and increment a counter until we have done a million iterations, and look at the execution time:
BEGIN
LET counter_variable NUMBER := 0;
WHILE (counter_variable < 1000000) DO
counter_variable := counter_variable + 1;
END WHILE;
END;
This took 31.4 seconds, which seems to indicate about 32 microseconds per loop. Some of the time may have been used to increment the counter variable, but that’s difficult to remove for this simple of a test.
REPEAT-loop
A REPEAT-loop will continue to loop until the condition becomes true.
REPEAT -- Statements to execute until the condition is true UNTIL (<condition>) END REPEAT;
For our testing, we simply loop and increment a counter until we have done a million iterations, and look at the execution time:
BEGIN
LET counter_variable NUMBER := 0;
REPEAT
counter_variable := counter_variable + 1;
UNTIL (counter_variable >= 1000000)
END REPEAT;
END;
This took 31.2 seconds, which seems to indicate about 31 microseconds per loop. Unsurprisingly, this is very similar to the WHILE-loop.
LOOP loop
A LOOP-loop will continue to loop until a “BREAK” command is executed.
LOOP -- Statements to execute until the condition is true END DO;
For our testing, we simply loop and increment a counter until we have done a million iterations, and look at the execution time:
BEGIN
LET counter_variable NUMBER := 0;
LOOP
counter_variable := counter_variable + 1;
IF (counter_variable >= 1000000) THEN
BREAK;
END IF;
END LOOP;
END;
This took 30.9 seconds, which seems to indicate about 31 microseconds per loop.
In the end, there is a multitude of LOOP styles to be used, and each has very little overhead in execution time. It is worth noting, however, how very efficient the iteration over a query result can be.
- FOR cntr: 30 µs
- FOR query: 20 µs
- WHILE: 32 µs
- REPEAT: 31 µs
- LOOP: 31 µs