
Tableau Prep has improved considerably since it was launched. It offers a lot of tools to pre-process and transform your data. But sometimes, you need to apply a function that has no equivalent in Prep, want to extract some data using an API interface or even apply some machine learning or natural language processing algorithms. With Python, you can do all of this and so much more, extending the power of Tableau Prep whilst staying within the boundaries of a Tableau Prep workflow.
Please note that using Python in Tableau Prep is different than using Python on Tableau Desktop. A blog on how to use Python in Tableau Desktop will be coming soon.
Use Case Example
I will explain how to use Python in Tableau Prep using the demo use case below, but before proceeding to the Python part, let me give you some background on what I am trying to achieve with Python in this particular case. For this demo, we will attempt to find out how much each of the 15 sales representatives in an imaginary company sold last year. We have two datasets: one with sales per account for last year and the other with the sales representatives assigned to each of our accounts:
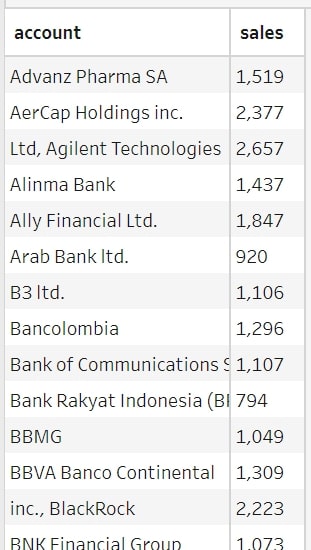
Above: Sales per account
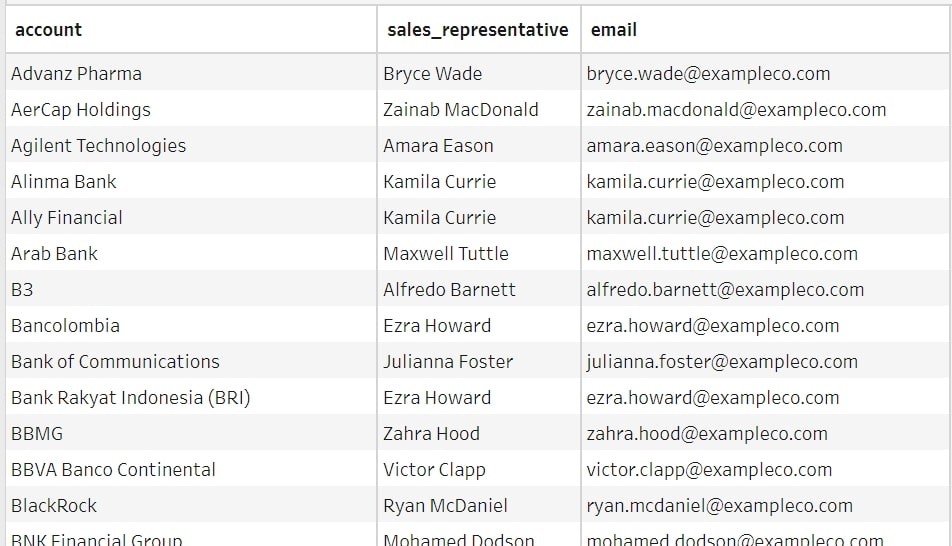
Above: Sales representatives responsible for each account
At first glance, the solution is straightforward: we simply have to join the two datasets on the account field, and we would have the amount of sales generated by each sales representative.
However, when attempting to join on account, we only join about 10% of accounts successfully. The others have not been joined because the names do not match correctly. Some account names have company types (e.g. Inc, Ltd, SA) as the prefix or suffix, and/or some contain typos in the company name. These are typical errors when entering company names manually.
We can go ahead and match each account manually in Prep, but this could take hours if we have hundreds of accounts. One way to go about this problem would be to use fuzzy matching, which is a technique of finding strings that match the pattern in a target string approximately rather than exactly. Unfortunately, fuzzy matching is not supported by default in Tableau Prep at the moment. Fortunately for our demo, we can do a fuzzy match using Python.
Setting up the TabPy Server
To use Python with Tableau Prep or Desktop, you, of course, need to have a distribution of Python installed. You also need to have TabPy Server library installed. I am using the Anaconda distribution of Python, so I will just go ahead and install TabPy Server by typing pip install tabpy in my Anaconda prompt:

This will also install the necessary dependencies. It is not required to have TabPy Server on the same machine that you are running Tableau Prep on, but it must be accessible for your Tableau Prep. To run the TabPy Server, we merely have to type tabpy in the Anaconda prompt:
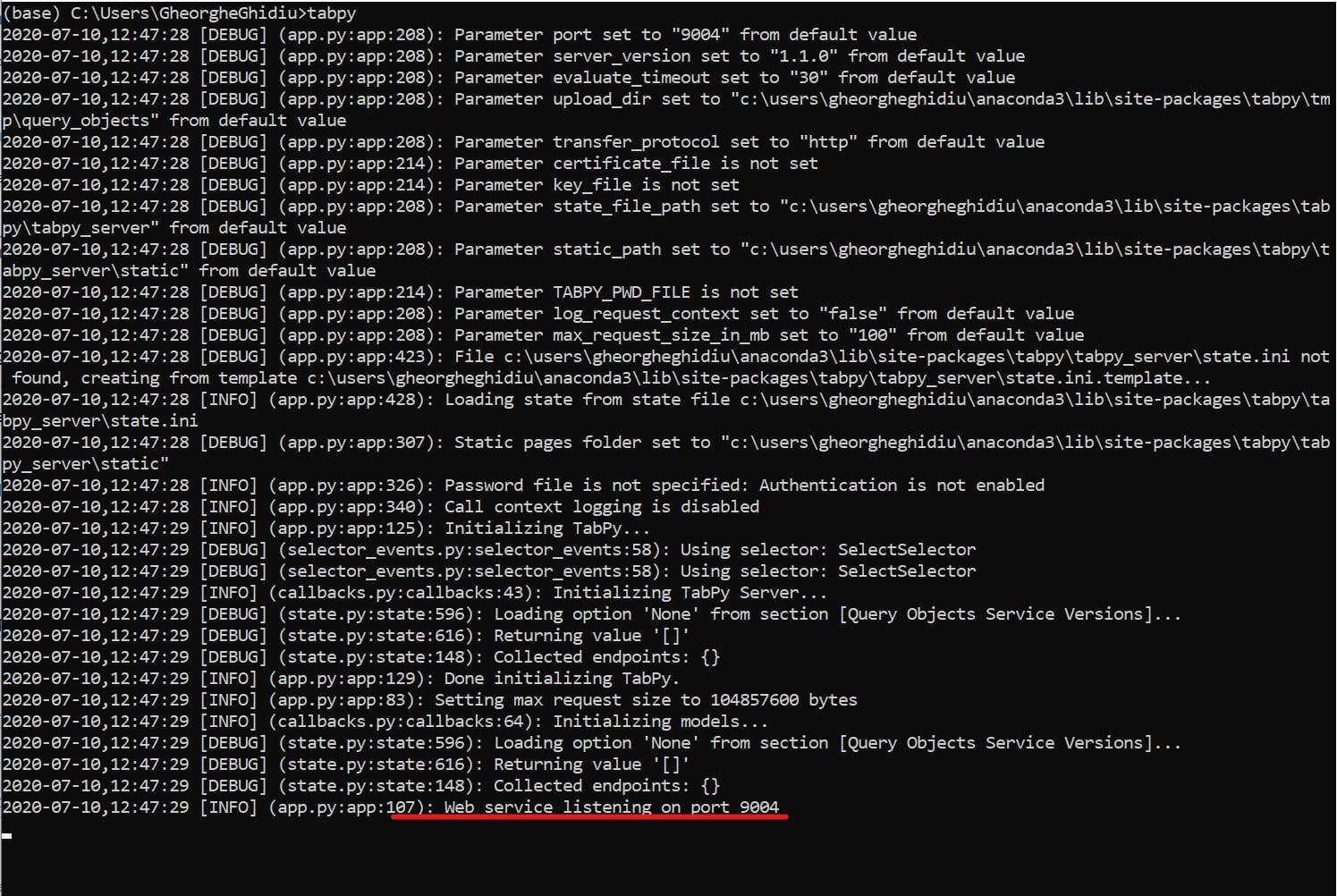
From the log, we can see that the TabPy Server has launched. What we are really interested in is the last line where we see that the server is running on port 9004, which is the default setting. The default settings can be adjusted according to your needs, but that is outside the scope of this post.
Optionally, to make sure the server is running, we can try accessing the port 9004 on our browser, which should look like this when the server is running:
Now we can begin our work in Tableau Prep.
Connecting to TabPy Server from Tableau Prep
To make use of Python in Tableau Prep, we need to add a Script step to our workflow:

Select the newly added Script step, and select Tableau Python (TabPy) Server as Connection type. Then click on Connect to Tableau Python (TabPy) Server in the configuration window:
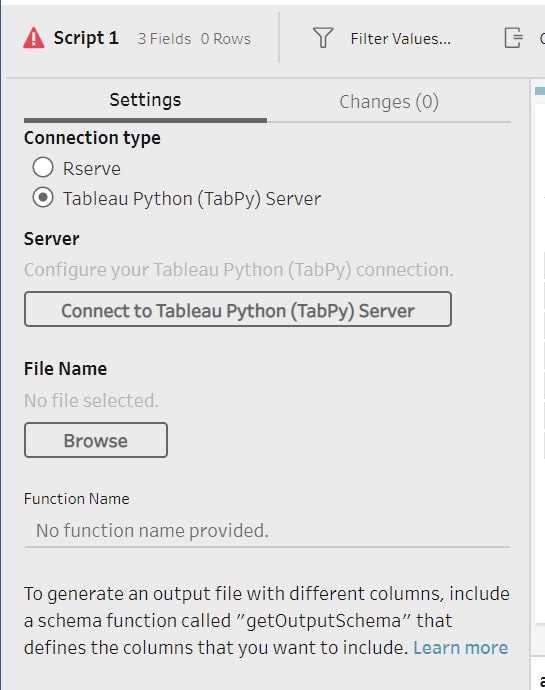
A connection configuration window will pop up like in the image below. Enter your server details here and click Sign In. In my case, the server runs on localhost port 9004, and no credentials are required. Now, we should be connected to the TabPy Server:
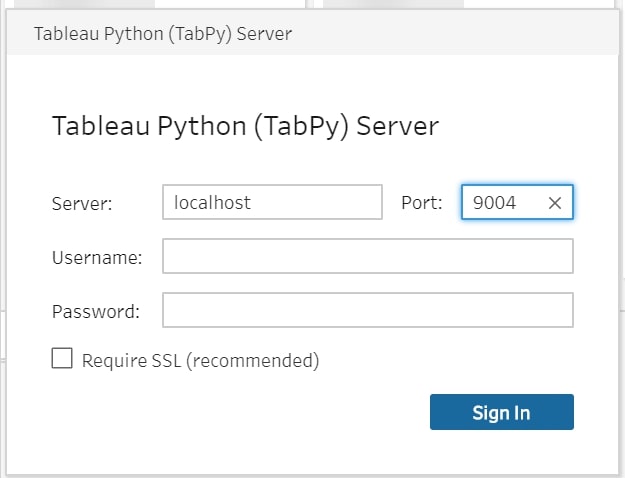
Running Your Python Code
It is not possible to type your Python code directly into Tableau Prep like you can in Tableau Desktop. Instead, you have to create a .py file with your Python code, which you will run from Tableau Prep.
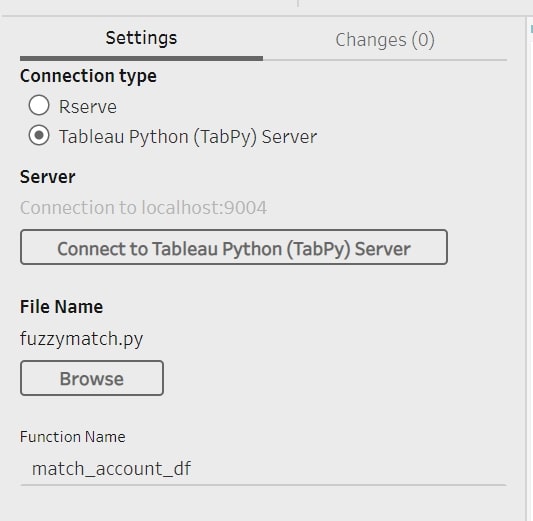
After you connect to the TabPy Server as described above, click on Browse to select the file with the Python code you would like to run. The last thing necessary for the configuration of the Script step is to specify the name of the function in your .py file that you want to apply to your data.
Please note that the function you specify must receive the entire dataset as the one and only argument. The data passed as the input to the Script step in Tableau Prep will be passed to the function as this one and only argument. You cannot select particular columns as arguments to this function or include additional arguments. Additionally, the function you are calling must return the entire dataset you wish to output from your Script step.
To make this more understandable, here is the Python script I am using with some explanations. For anybody unfamiliar with Python, the lines that begin with a # are the comments explaining what the code does:
#required libraries for my use case
import pandas as pd
from fuzzywuzzy import fuzz
#read in the csv with the list of accounts because ...
#Tableau Prep does not support multiple inputs for script steps
#so you have to read additional datasets in python
sales_df = pd.read_csv(r"C:\Users\...\Sales.csv")
list_of_accounts = sales_df.account #we only need the account column
#function to match a single account - I am not calling this function directly in Prep ...
#because it cannot take the entire dataframe as an argument and it does not output the desired data.
#instead I use this function inside the function that I am calling from Prep
def match_account(account, accounts_list, min_score=0):
# -1 score incase we don't get any matches
max_score = -1
# if no match is fount
max_account = ""
#iterating through the accounts in the other dataset
for new_account in accounts_list:
#fuzzy match score
score = fuzz.ratio(account, new_account)
#check if the score is above the min and that there is a match
if (score > min_score) & (score > max_score):
max_account = new_account
max_score = score
return max_account
#function to create the column with newly matched accounts and output the new dataframe
#this function is called in Prep
def match_account_df(input_df):
#use a min matching score of 40 to exclude bad matches but still include short names (e.g. B3)
input_df['account2']=input_df['account'].\
apply(match_account, accounts_list=list_of_accounts, min_score=40)
output_df = input_df
#return the entire df
return output_df
#encoding function to define the schema of the output_df (explained bellow)
#the actual dataframe schema output by the function above must match your encoding
def get_output_schema():
return pd.DataFrame({
'account' : prep_string(),
'account2' : prep_string(), #this is our new column
'sales_representative' : prep_string(),
'email' : prep_string()
})
#data types for the get_output_schema:
# prep_string() --> String
# prep_decimal() --> Decimal
# prep_int() --> Integer
# prep_bool() --> Boolean
# prep_date() --> Date
# prep_datetime() --> DateTime
After you type the name of the function and press enter, as in the image below, Prep will automatically start running your Python code and either show you the results in the preview or specify the errors in your code. When you save your workflow, the connection details will be saved automatically, so you do not have to enter them every time:
The encoding function in the code is there to define the output schema for the Script step. You do not have to call this function anywhere. Simply write it in your script with the standard name get_output_schema() and the schema you need, and Prep will automatically make use of it. If you do not type the encoding function in your script, Tableau Prep will reuse the schema from the input to the Script step. In this case, the Script step will run without any errors, but you will not see the newly created columns in the output.
It isn’t always necessary to write the encoding function in your script. For example, if your table contains many columns, and your Python script simply adds another column, then you would have to type all the columns you already have, plus the new column in the get_output_schema() function just to make a small change (i.e. add a new column). For such a scenario, before the Script step, you can create an empty column with the same data type and name, as shown in the example below:
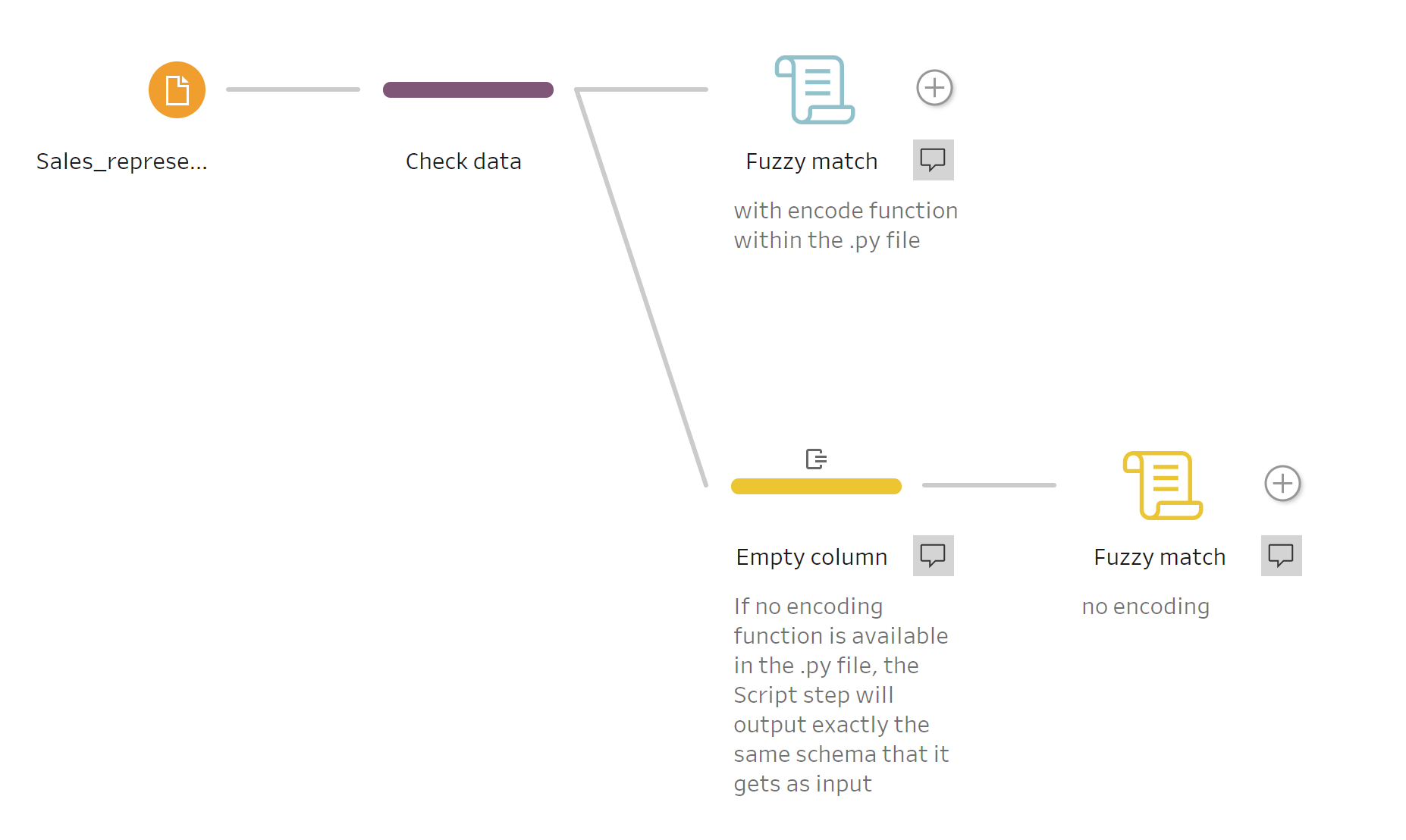
The two parallel workflows above lead to the same result. The difference is that the first contains the following encoding functions in the Python script:
def get_output_schema():
return pd.DataFrame({
'account' : prep_string(),
'account2' : prep_string(), #this is the new column
'sales_representative' : prep_string(),
'email' : prep_string()
The latter workflow does not have the encoding function above. Instead, it has a Clean step before the Script step where the new empty string column is created, like so:
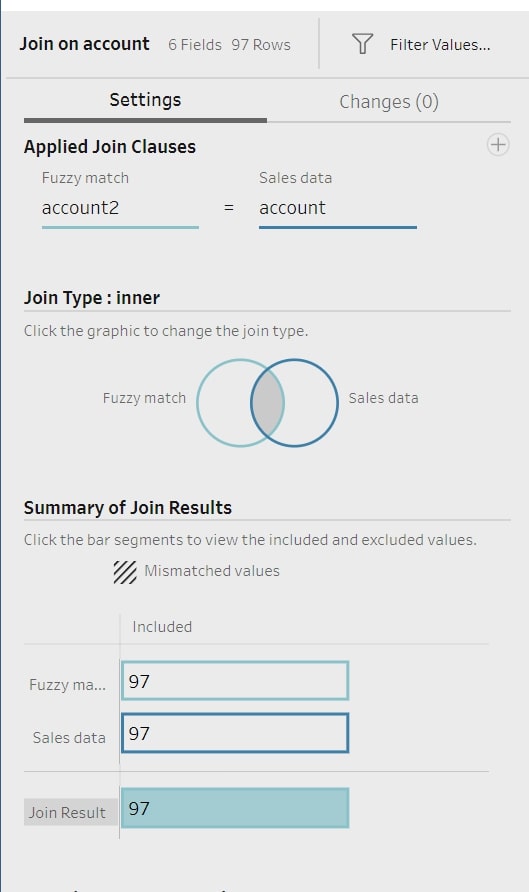
After fuzzy matching the data, we can easily join it with the sales data. This time, we get no mismatches and the desired data structure is achieved:
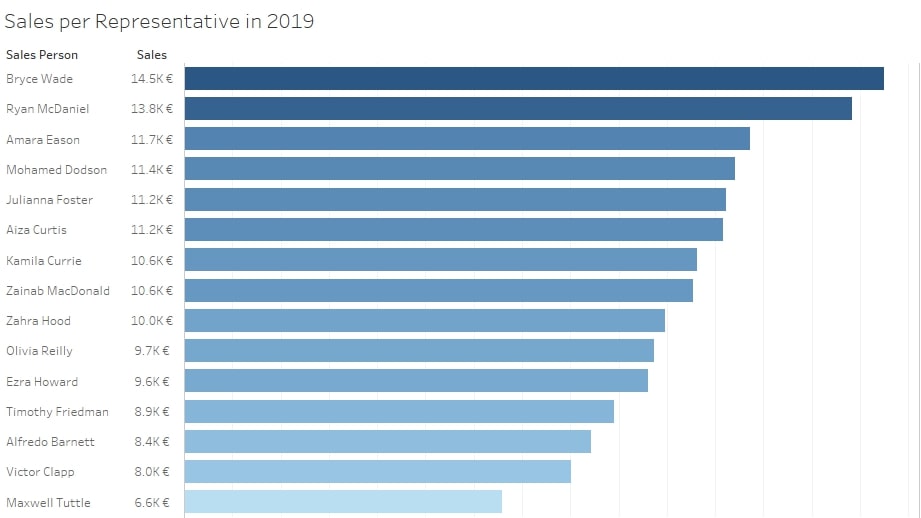
Now, we can plug this dataset into Tableau and discover the amount of sales each representative generated last year. Looks like Bryce and Ryan are leading with around 14K worth of sales each:
This was just a small example of how we can extend the functionality of Tableau Prep by using Python. When harnessing the power of Python in Tableau, the possibilities are virtually endless, and there are many more use cases where you can see the value of Python. To learn more about how these solutions work together, or if you found this post helpful, stay tuned for an upcoming blog on how to use Python in Tableau Desktop.